Hi everyone! We’ve just shipped a really cool update to our x86/x86-64 emulation stack on Asahi Linux, and I wanted to share what we’ve been working on. As of today, non-game apps are now usable!
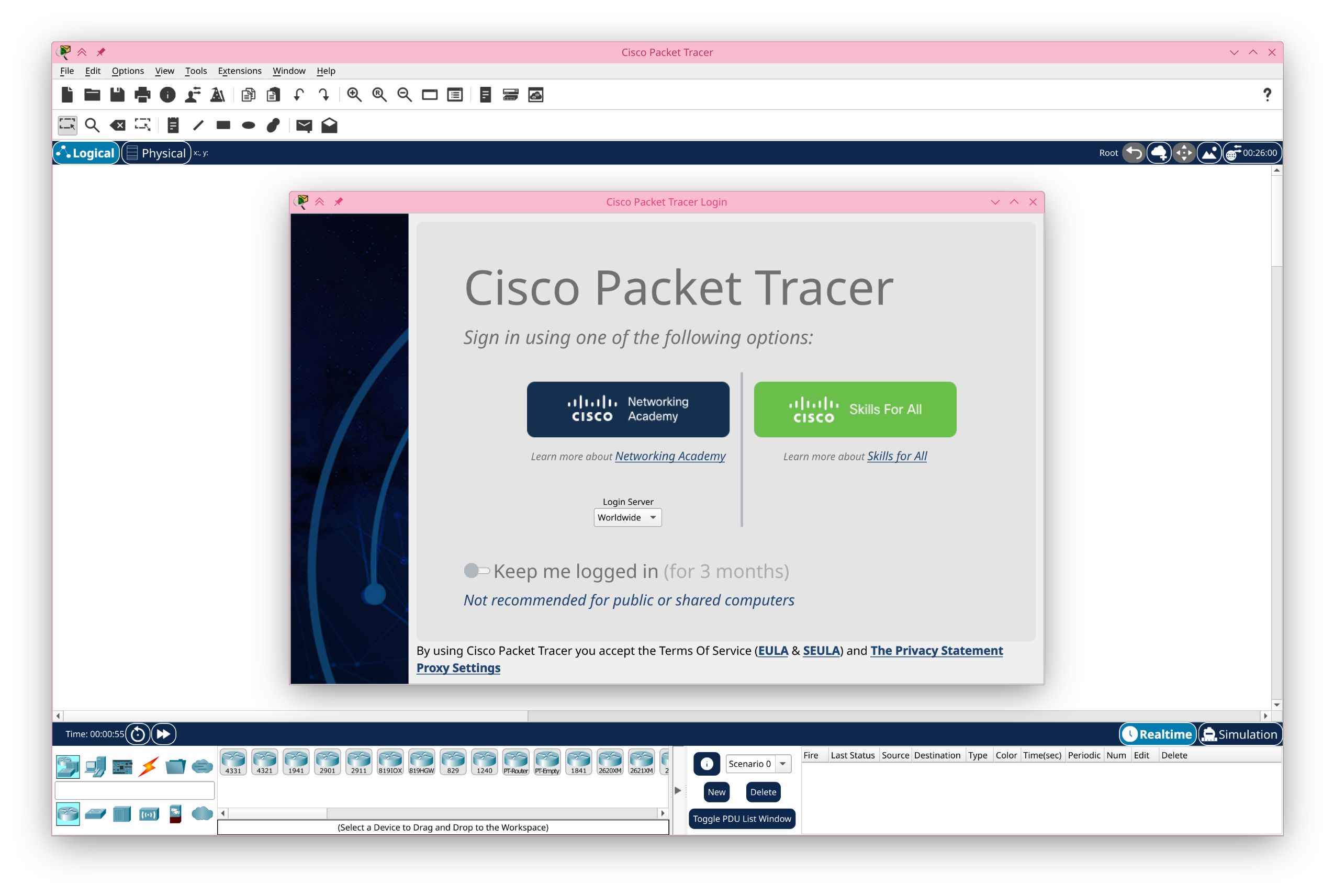
Cisco Packet Tracer running on Fedora Asahi Remix
Native graphics in VMs
As you might remember from our previous blog post, Asahi Linux runs all x86/x86-64 apps in a microVM driven by muvm. How can we manage to run games in a real VM with near-native performance, without hardware GPU passthrough?
On AMD/Intel systems (and, indeed, also on macOS on Apple Silicon), GPU virtualization has always been kind of limited. Your options are to either fully pass through the hardware GPU, or use API-level GPU paravirtualization. Passing through the hardware GPU fully assigns the GPU device to the guest, which means it sees it as a “real” GPU device. This works for all guest OSes that have real drivers for that GPU, and it has native performance, but it means the GPU is dedicated to the guest, so you can’t share it with the host or integrate guest and host windows together on one screen. Meanwhile, API-level GPU paravirtualization essentially sends the OpenGL, Vulkan, or Metal commands from the guest to the host, so they are processed by the host’s GPU driver stack. This requires “generic” paravirt GPU drivers in the guest, and it is much slower than native GPU usage because all the high-level GPU drawing commands have to cross the guest-to-host barrier and be processed on the host. This is how GPU virtualization works on macOS. Some GPUs (e.g. recent Nvidia GPUs) support true sharing with hardware virtualization support, but that isn’t upstream yet and requires hardware support, which Apple GPUs don’t have.
But what if there was a better way? It turns out, there is! Enter DRM Native Context.
The concept is quite simple: Instead of running the entire GPU driver stack on the guest and passing through the whole hardware GPU (no sharing), or running the entire GPU driver stack on the host and passing through high-level APIs (slow), why not split it down the middle? DRM Native Context runs the GPU kernel driver on the host, and the GPU userspace driver (Mesa) on the guest, and passes through the kernel UAPI interface from the guest to the host.
This gives us the best of both worlds: Since the GPU userspace drivers run in the guest, they can run with full performance just as if they were driving a real, hardware GPU. And since the GPU kernel driver runs in the host, it can be shared between host applications and guest applications. A simplified render operation might go like this:
- The application issues GL or Vulkan draw commands to draw things on the screen. A game might perform thousands of these per frame.
- The userspace Mesa driver in the guest takes these commands and converts them to GPU command structures. These command structures are written directly into GPU memory which the driver has previously mapped directly from the host using the virtio-gpu protocol, so it’s just as fast as running natively.
- The application flushes the draw stream or otherwise requests the GPU begin rendering.
- The userspace Mesa driver prepares the overall render information, the same way it would if running natively on the host.
- Mesa then wraps the command in a virtio-gpu execution buffer, which has the information needed to pass through the command to the host.
- The command, which is only a kilobyte or two of data at most, travels via the guest kernel virtio-gpu driver into the host virtual machine monitor.
- The VMM receives the command and passes it on to virglrenderer, which unwraps the native UAPI GPU command structure.
- virglrenderer issues the
ioctl()to pass through the command to the host GPU kernel driver. - The host GPU kernel driver sends the command to the GPU.
The process to render natively on the host is exactly the same, except it removes steps 5 through 7 (in step 8, Mesa would issue the ioctl() directly). Therefore, the overhead is quite small, since the extra guest-to-host communication only involves a tiny amount of data, instead of having to pass through entire GL or Vulkan command streams. It also means we can run the same exact drivers as we would natively, so we know the GPU features should be exactly the same, with the same GPU driver quality and compatibility.
What about security and isolation? Each process on the guest is handled as an independent GPU process from the point of view of the host kernel driver (more specifically, each time a guest process opens the virtual GPU device node, the host VMM opens the real GPU device node for it as a separate file descriptor). This means that guest GPU processes are isolated just as native GPU processes are from each other.
As of today, DRM native context is only upstream for freedreno, so you’ve probably never heard of it if you’re used to x86 machines! However, PRs are in flight for Intel and AMD GPUs, and I think this really is the future of GPU virtualization for Linux guests on Linux hosts (and perhaps, some day, Windows guests running Mesa on Windows)!
We shipped DRM native context with our gaming update in October, and the results speak for themselves.
So where’s the catch? As you might expect, performance isn’t quite native. The performance impact comes from synchronization: Sending commands to the GPU takes a little bit longer, and waiting for GPU commands to complete takes a little bit longer. Applications that “fire-and-forget” lots of GPU work all at once will see nearly native performance, while applications that wait for GPU work to complete often will suffer increased latency and lower throughput. Applications that use multiple GPU queues and synchronize between them will also suffer today, as that synchronization happens through the VM guest, but we plan to improve this by moving GPU-to-GPU synchronization to the host kernel just as it would happen for native apps (we just haven’t implemented this yet).
But just getting GPU rendering to work in the guest is only half the story…
Window systems attack
While DRM native context by itself lets the guest render on the GPU, we haven’t talked about display yet! It would be possible to use a virtual screen device like a traditional VM and have the guest show up as a whole separate desktop in a window, but that’s not what we want for our stack. We want the VM to be a thin layer, and applications to show up natively on the host window system.
Crosvm, the ChromeOS VMM that muvm and libkrun’s graphics support shares code with, does this using a feature called cross-domain contexts. virtio-gpu lets the guest open a communications channel, which the host VMM can then forward to a host compositor. Crosvm uses this to implement Wayland forwarding using a guest Wayland compositor called sommelier. sommelier listens on the Wayland socket on the guest, and forwards the requests to the host Wayland compositor. Forwarding just the protocol isn’t enough (otherwise you could do this using virtio vsock or TCP or anything else): sommelier needs to also extract buffer file descriptors that are passed through as part of the Wayland command stream, and use virtio-gpu mechanisms to directly share them between the host and the guest. This allows window framebuffers to be shared, so they can be composited on the host without any extra copying cost. On the host VMM side, this is handled by the cross-domain component of rutabaga_gfx, which implements the commands to forward the Wayland protocol and convert shared buffers back to fds that the host Wayland compositor can understand.
There was one extra catch: Synchronization. When a GPU app on the guest renders to a buffer, it passes it directly to the host before waiting for the rendering to finish. A mechanism called implicit sync is supposed to let the kernel handle synchronization directly: The kernel knows what GPU operations are pending on the buffer and makes the GPU wait until they complete before reading from it in another context. Implicit sync is considered a legacy feature, so our GPU kernel driver does not implement it, but instead we implement it in Mesa for compatibility (Nvidia refused to do this, and this is why Wayland was broken on Nvidia GPUs for so long…). Our Mesa driver inserts implicit sync information (GPU fences) into shared buffers automatically when they are a render target, and extracts the fences on the other end before reading from the buffer. This worked great on both the host and guest, but did not work on buffers shared between the host and the guest: When guest Mesa inserted a fence in the guest buffer, that fence was only registered in the guest kernel, so the host kernel had no idea about the ongoing render and couldn’t hand back the fence to the host Mesa when needed. This caused tearing, visual glitches, and “frame lag”. To fix this, I ended up just going back to implicit sync for now: The Asahi virtgpu protocol now includes a buffer list with submissions just like “classic” implicit sync drivers, and those buffers have fences registered for them in the host VMM, in virglrenderer code. The implicit sync compatibility code runs twice, once in the guest Mesa and once in the host VMM, to cover all the bases. In the future, we do plan to implement explicit sync properly, integrate it with the cross-domain stuff, and remove this hack, but that will have to wait a bit, since it needs non-upstreamed guest kernel patches… but I digress.
What about X11? Most games need X11 to run, so sommelier can run its own XWayland instance in the guest to provide X11 support. Easy, right?
We shipped this solution in October and… it didn’t go so well.
Sommelier woes
As it turns out, sommelier isn’t quite as nice a solution as we’d hoped. It is designed to be used in a ChromeOS host, and it doesn’t work quite as well on more general Linux desktops.
sommelier both does too much and too little. It is quite a complicated piece of code, doing lots of Wayland protocol parsing, buffer copying, and more. This means that applications on the guest don’t quite act as applications running natively on the host. There were lots of problems with things like DPI scaling and window/popup placement. At the same time, sommelier doesn’t do enough to integrate with XWayland. On popular Wayland desktop environments like KDE Plasma, the compositor does a lot of extra work to integrate with X11 applications properly, talking directly to XWayland to manage them. None of this works with sommelier, which provides only bare-bones X11 integration. X11 apps are missing title bars, menus don’t work properly, the clipboard doesn’t work properly, there is no system tray integration, some windows showed up weirdly transparent…
On top of that, sommelier is written in C and doesn’t fully isolate client connections. It generally works well enough with an XWayland client, but oddities can cause it to crash and bring down the whole VM environment. Native Wayland proxying was out of the question: We tried it and it was too broken to be usable at all.
So, we decided to ship with sommelier and XWayland as an X11-only solution (no Wayland socket support), and advertise it as a game-only solution, since full-screen apps generally worked well enough. This meant running Steam in Big Picture mode (since windowed mode was quite broken). It also meant that games that used windowed launchers often weren’t usable.
But we needed a better solution.
X11 first?
Back before muvm was even called muvm, I had experimented with direct X11 forwarding over virtio vsock sockets. This works much like running X11 over the network or an SSH tunnel. The disadvantage of this is that it can’t work with GPU acceleration, since there is no way to pass through GPU buffers over a “dumb” socket like this. Still, running some apps while forcing software rendering, it was clear that this was a much better solution for non-game apps. X11 apps worked exactly as they did on the host, with no window management issues, properly working clipboard and tray integration, etc.. I was prepared to ship this is an alternative for non-game apps as-is, but I wondered how hard it would be to get GPU acceleration working… and then chaos_princess showed up with something they called x112virtgpu.
x112virtgpu, now renamed to muvm-x11bridge, is exactly what we would have wanted sommelier to be: A thin proxy for the X11 protocol, which uses a cross-domain channel to forward directly to the host X server while passing through framebuffers without any copying, using virtgpu buffer sharing. Unlike sommelier, it doesn’t try to interpret the X11 protocol more than is necessary to extract commands that need special handling. This means that it works just as well as direct X11 passthrough does, plus GPU acceleration and buffer sharing.
… or that’s the theory anyway. There was one teeeeeny catch…
Futex what?
The X11 protocol is quite peculiar. Besides passing through framebuffers using file descriptors, it also passes through something else: fences. No, not modern GPU explicit sync fences (those are supported too in X11 as of very recently, but that’s another story). CPU-side fences, which are implemented using… futexes.
Whaaa?
Futex is a kernel system call for doing cross-thread and cross-process synchronization on Linux. It’s basically a build-your-own mutex primitive. The two threads or processes are supposed to share memory directly, and synchronize using atomics. When one process needs to wait for another, it uses the kernel futex() system call to put itself to sleep, and when another process needs to wake it up, it uses the same system call to do so. The kernel makes sure the system calls are synchronized with the actual value of the shared memory, so there are no race conditions.
We need to make this work between host and guests processes… but there’s no such thing as a cross-domain futex() system call. The host and guest kernel have no idea about each others’ futexes. And to make this work at all, we need to share the memory…
We could solve this problem at a high level, interpreting the X11 protocol more to understand exactly what futex fences are used for. Each side, host VMM and x11bridge, would have to understand which side is responsible for signaling and waiting on a futex. Then, the proxy components on the signaling end would have to wait for the signal, then send a cross-domain command to forward that signal to the other end. This would work, but it would both be a lot of work, and add extra latency: The futex mechanism is supposed to work without any system calls at all if one side isn’t waiting on the other, by using atomic operations directly.
So chaos_princess decided to try something else: What if we could actually share memory? If the host and guest processes could actually map a shared memory buffer together, then they could use atomics just as if they were both running on the same side, and then we’d only have to proxy the futex() system call usage somehow. This turned out to be viable, but how can we share memory? We could use GPU buffers, but that seems a bit excessive, and not really possible to integrate directly with the X server and clients…
The library in charge of handling X11 shared-memory fences is libxshmfence. This library can use multiple mechanisms to share memory. On Linux, it defaults to memfd(), which is a system call that creates “in-memory” files. Can we share those across the VM boundary? Unfortunately, not easily.
But there is another way.
In muvm, we already share the host filesystem directly to the guest. This is essentially a FUSE filesystem proxied across to the VM. Normally, this works by copying data around when reading and writing files. However, there is a special mode, called virtiofs DAX, which allows the guest to directly map host files into memory! When a filesystem is shared and mounted with DAX, a mmap() in the host and in the guest of the same file will actually share memory directly, and atomic operations will work between the guest and the host! How cool is that?
As it turns out, DAX is kind of new and slightly broken, and I ended up having to send several patches to both libkrun and the guest kernel to get it to work reliably (we’re still figuring out how to upstream some of those…). But once it worked, it meant that we could directly share memory between the guest and the host. muvm now does this by mounting /dev/shm in the guest with DAX support, so the host and the guest can share POSIX shared memory.
But… libxshmfence still insists on using memfds. How do we fix this?
chaos_princess, true to their name, decided to go full chaos mode with their solution: ptrace! When muvm-x11bridge gets a memfd from a client process, it ptraces it and injects the necessary system calls to open a /dev/shm file and swap out the file descriptors as if nothing happened. Then the filename can just be passed to the host, where libkrun can open it and hand the fd to the X server as if nothing happened.
Then, muvm-x11bridge runs a little futex watcher thread, which detects futex() wakeup calls from the client process and sends wakeups to the host, which can forward them to the X server.
Madness! But it worked… kind of? It took quite a while to debug this whole setup, since the ptrace() dance was very finicky and it took several tries to make it work well, and the futex() proxying also turned out to be quite hard to get right. We did get it to work quite reliably in the end, but there is a significant limitation: You can’t use ptrace for other purposes with X11 client apps, since it will break muvm-x11bridge. This means you can’t use strace to debug things, and some complicated apps that like to use ptrace (like Chromium and Chromium-based apps) would run into trouble.
One possible alternative would be to use LD_PRELOAD to hijack libxshmfence, and this is another solution that chaos_princess implemented… but since we’re also doing this whole thing across 3 architectures (native arm64, emulated x86, and emulated x86-64), we’d have to ship three versions of the library, and this solution is also not guaranteed to work properly with container technologies.
We needed a better solution if we seriously wanted to ship this…
Futexes, take 2
Looking closely at the libxshmfence code, it turns out there are several fallback paths if memfd() does not work. First, it uses shm_open(SHM_ANON, ...), but that’s a BSD thing and not available on Linux. Then, it tries open() with O_TMPFILE, but O_TMPFILE is not supported by virtiofs. Finally, it does it the old-school way, by opening a file in /dev/shm and unlinking it. If we could get it to just not use memfd(), it would do exactly what we want. Can we?
I tried several things, including using a seccomp-bpf filter to disable the memfd() system call. Unfortunately, that breaks stuff like some codepaths in FEX, which assume memfd() exists and is working (which is a pretty reasonable assumption on any modern Linux kernel).
Sooo… I ended up just sending a little merge request to libxshmfence to allow disabling memfd() usage using an environment variable… and it was merged!
This patch is not released as a new libxshmfence version yet, so any distributions that want to ship the new muvm version will have to backport this patch to their libxshmfence packages at this time, to avoid falling back on the less-reliable ptrace() hack.
We’re done, right? Not quite… libxshmfence still deletes the shared memory file and passes only the fd to the X11 server. That’s desirable (it avoids risking leaving stale files around in error cases), and we don’t want to introduce more hacks into libxshmfence… so how do we pass the fd to the host side if we can’t reopen the file?
Well… if you think about it, even if the file is deleted, every fd open in the guest is actually opened by the host VMM. That’s how virtiofs works! So the host already has the file descriptor we need somewhere… we just need to find it. To make this work, I ended up adding a magic fd-export ioctl() to the virtiofs implementation in libkrun. This works sort-of like exporting GPU buffers and gives you an identifier that you can pass to the host as part of the X11 cross-domain protocol, which can then reference a special table of exported file descriptors to locate the underlying host fd. This is implemented by sharing the exported-fd table between the virtiofs code and the rutabaga_gfx cross-domain code, which is quite a few layers of code to plumb it through… but Sergio was happy enough with this solution and merged my PR ^^.
Finally, after a lot more debugging of the futex and cross-domain X11 code, it was finally stable and ready to merge and release!
What about Wayland?
In the future, we’d also like to support native Wayland passthrough. To do this, we’ll need a Wayland counterpart to muvm-x11bridge. Unlike sommelier, this is planned to be much simpler and follow the same philosophy, and we expect it to work as well as X11 passthrough. However, we should probably get the fencing and explicit sync stuff worked out first, so pure Wayland passthrough will remain on the to-do list… for now. The good news is it doesn’t have any weird futex stuff!
Muvm, reloaded
If you update your Fedora Asahi Remix system today with sudo dnf update --refresh, you’ll get all these improvements to our x86 emulation stack over the October release:
muvm changes
muvm-x11bridgefor direct X11 passthrough (you can use--sommelierto revert back to sommelier, but why would you?).- Steam and other windowed apps now work properly, and even the system tray icon works.
- You can also use CJK input methods in Steam using good old XIM, if they are configured properly on the host! (Tested with fcitx on KDE Plasma.)
muvm-hidpipeis now integrated, so gamepads will work without using oursteamwrapper. In fact, after Steam is installed once, you can run it withmuvm -- FEXBash -c '~/.local/share/Steam/steam.sh'without any loss of functionality./dev/shmis now shared between the host and the guest, enabling interesting use cases.- Guest memory is now better managed, which should lead to fewer host OOMs.
- 8GB machines default to a higher memory allocation, which makes more games playable on those.
- Interactive mode to run commands within an already-running VM. For example, run
muvm -ti -- bashto get a shell. - You can also run commands as root by connecting to the root-server port:
muvm -tip 3335 -- bash. - Lots of little improvements and fixes.
FEX changes
- Many bugfixes and improvements, including fixes for the new Steam CEF update.
virglrenderer & Mesa changes
- Vulkan 1.4 support
- Many bugfixes and performance improvements
steam wrapper changes
- Steam now starts in regular windowed mode, instead of Big Picture mode.
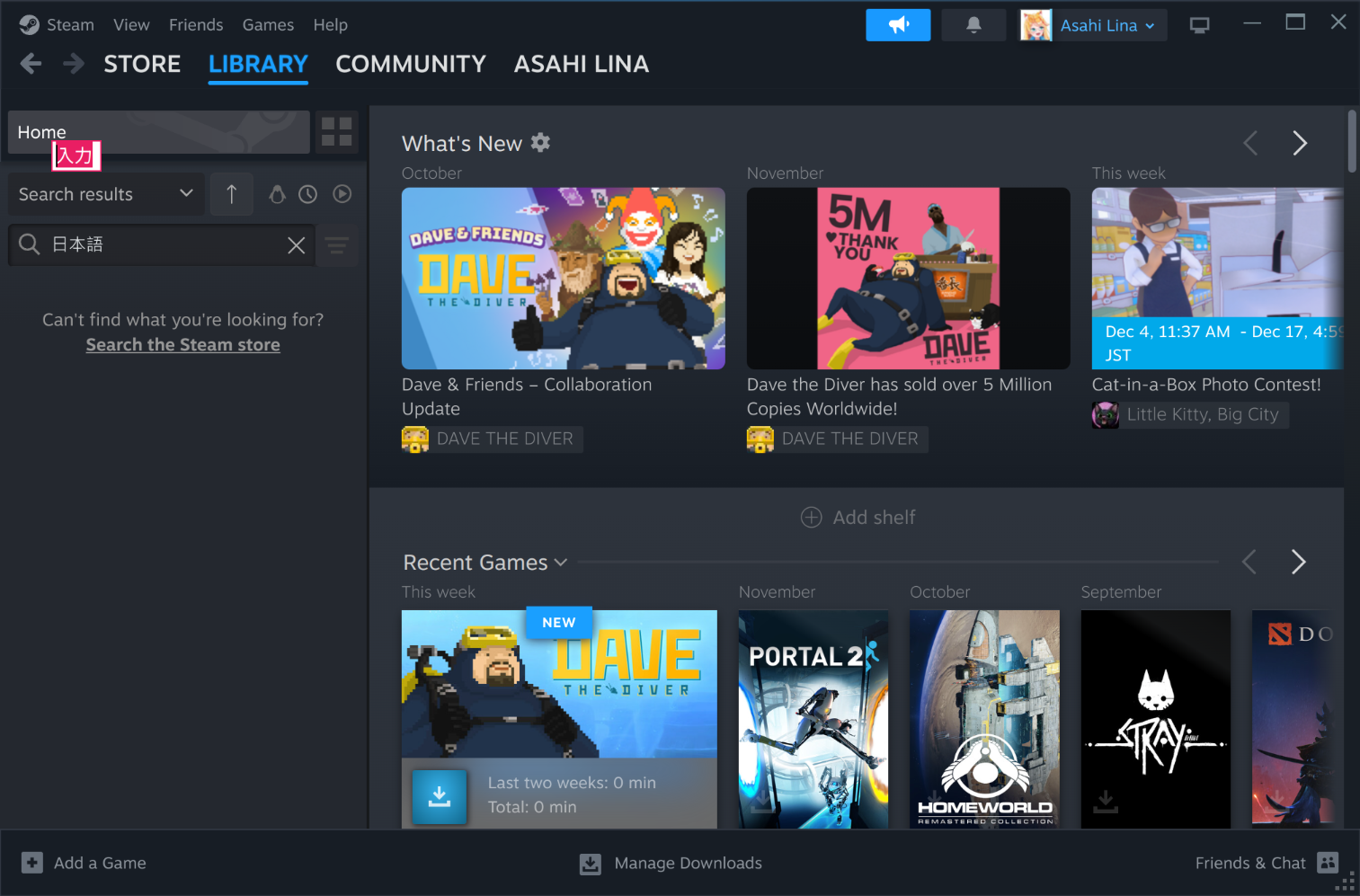
Steam with the standard windowed UI, with working Japanese input
We have also automated the installation of all the required bits and pieces to run non-Steam applications, so you don’t need our steam package if you don’t want to run Steam. Just update your system first as above, then sudo dnf install fex-emu to get everything you need to run x86 and x86-64 applications with muvm.
Now that window management works reasonably well, we encourage you to try non-game apps. In general, applications packaged as stand-alone tarballs (without complex OS dependencies or interaction with other applications) are likely to work well, including AppImages. Note that Flatpak does not integrate with FEX/muvm, so x86-64 Flatpaks will not work yet. Let us know how well it works for you!