Hello everyone, Asahi Lina here!✨
As you probably know, I’ve been working together with the rest of the Asahi Linux team on open source GPU drivers for Apple Silicon platforms. It’s been a wild ride! Just at the end of last year we released the first version of our drivers, after many months of reverse engineering and development. But that was only the beginning…
Today we’re releasing a big update to our GPU drivers for Asahi Linux, so I wanted to talk to you about what we’ve been working on since then, and what’s next!
If this is your first time reading about our GPU adventures, you might want to check out my Tales of the M1 GPU article first, which covers what I worked on last year! Also don’t miss Alyssa’s amazing series of articles on her website, which goes all the way back to January 2021! ^^
And if this is too long, feel free to jump to the end to learn what this all means for Asahi Linux!
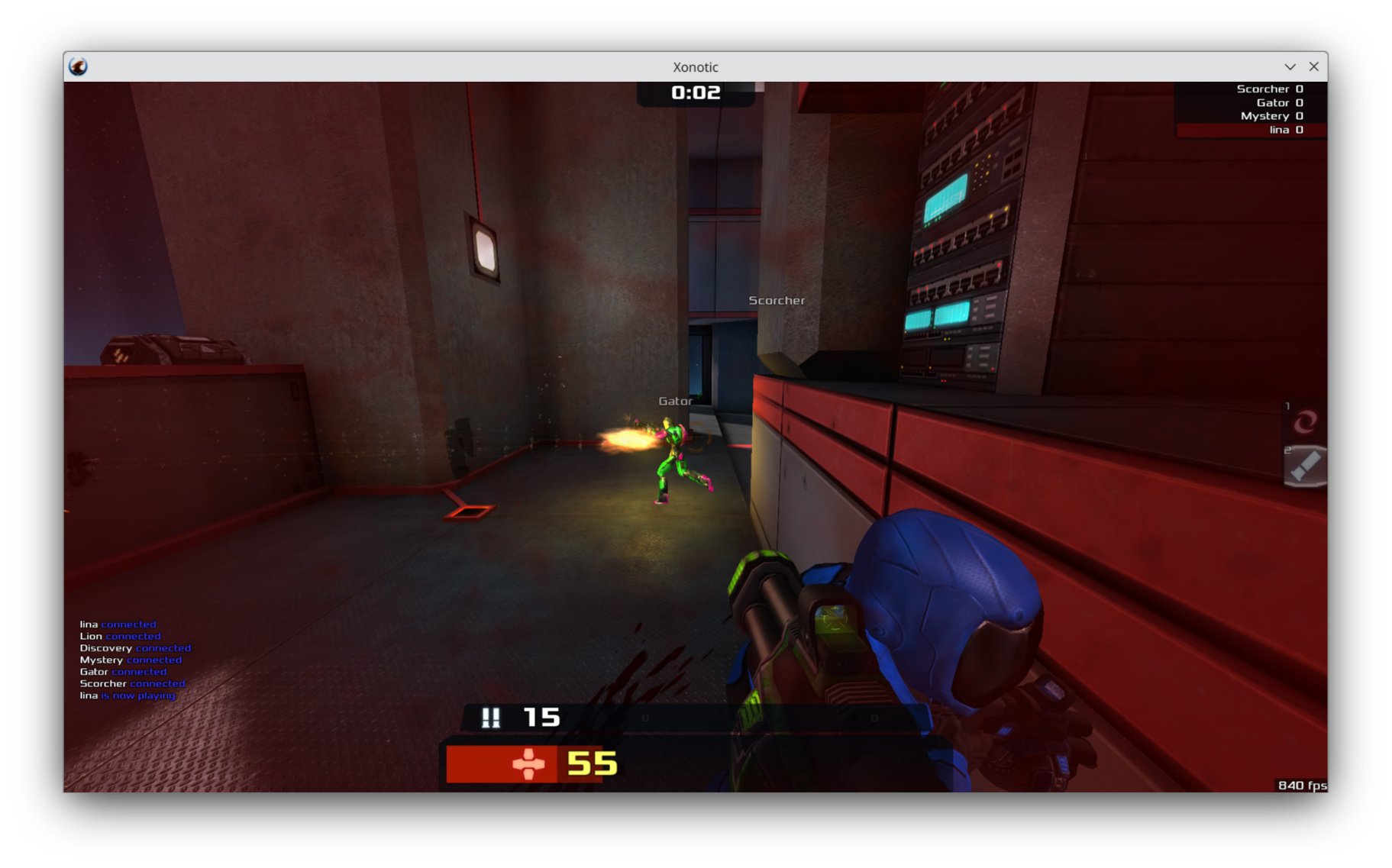
Xonotic running at 800+ FPS on an Apple M2
What’s a UAPI?

In every modern OS, GPU drivers are split into two parts: a userspace part, and a kernel part. The kernel part is in charge of managing GPU resources and how they are shared between apps, and the userspace part is in charge of converting commands from a graphics API (such as OpenGL or Vulkan) into the hardware commands that the GPU needs to execute.
Between those two parts, there is something called the Userspace API or “UAPI”. This is the interface that they use to communicate between them, and it is specific to each class of GPUs! Since the exact split between userspace and the kernel can vary depending on how each GPU is designed, and since different GPU designs require different bits of data and parameters to be passed between userspace and the kernel, each new GPU driver requires its own UAPI to go along with it.
On macOS, since Apple controls both the kernel driver and the userspace Metal/GL driver, and since they are always updated in sync as part of new macOS versions, the UAPI can change whenever they want. So if they need a new feature to support a new GPU, or they need to fix a bug or a design flaw, or make a change to improve performance, that’s not an issue! They don’t have to worry too much about getting the UAPI right, since they can always change it later. But things aren’t so easy on Linux…
The Linux kernel has a super strict userspace API stability guarantee. That means that newer Linux kernel versions must support the same APIs that older ones do, and older apps and libraries must continue working with newer kernels. Since graphics UAPIs can be quite complicated, and often need to change as new GPU support is added to any given driver, this makes it very important to have a good UAPI design! After all, once a driver is in the upstream Linux kernel, you can’t break compatibility with the old UAPI, ever. If you make a mistake, you’re stuck with it forever. This makes UAPI design a very difficult problem! The Linux DRM subsystem even has special rules for GPU UAPIs to try to minimize these issues…
UAPI baby steps
When I started working on the driver, my first goal was to figure out how the GPU and its firmware worked, and how to talk to them (the “Firmware API” in the diagram). First I wrote a demo in Python that ran remotely over USB and could render single frames, and then I realized I wanted to try hooking up Alyssa’s Mesa driver to it directly so I could run real demos and test apps. Mesa already had a testing tool called “drm-shim” which can “fake” the Linux DRM UAPIs, so all I had to do was plug a Python interpreter into it! But we didn’t have a UAPI yet for our driver…
So I copied and pasted the Panfrost UAPI, simplified it a bit, and ran with that! Since drm-shim isn’t a real Linux kernel, and since my Python driver was just a demo all running in a single process, there was no parallelism possible: when the app submits a command to the GPU, the Python driver runs it immediately, and doesn’t return to the app until everything completes. This didn’t matter at all at the time, since running everything over a USB connection was a much bigger bottleneck!
As I reverse engineered more things about the GPU, I figured out how to do parallelism properly, and I had several Python-based demos that could run several things on the GPU at once. And so, when it came time to write the real Linux driver in Rust, I mostly knew everything I needed to design it to do that! The Rust driver’s core supported running multiple things at once, and indeed with our release in December, you can run multiple apps that use the GPU at once and they can (in principle) submit work to the GPU in parallel, without blocking each other. But… I already had the “demo” UAPI hooked up into Mesa, so at the time… I left it as-is!
What was the issue with that UAPI? Just like the Python demo, the whole GPU rendering process was synchronous: when an app submitted work to the GPU it would be queued to be executed by the firmware, then executed, and only when everything was complete would the UAPI call return back to the app. That means that the CPU and the GPU couldn’t process anything in parallel within a single app! Not only that, there is some latency to going back and forth between the CPU and the GPU, which reduced performance even more…

Thankfully, both the GPU and the CPU are so fast that even with this terrible design, things still ran fast enough to give us a usable desktop at 60FPS. 🚀
But this clearly wouldn’t do, and it would be a terrible design to try to upstream, so we had to come up with something better.
GPU Synchronization
Once you start running things in parallel, you run into the issue of how to keep everything synchronized. After all, after the CPU submits work to the GPU, it might actually have to wait for it to finish at some point before it can use the results. Not only that, different bits of work submitted to the GPU often depend on each other! These dependencies can even extend across apps: a game can queue multiple render passes that depend on each other in a complex way, and then the final scene has to be passed to the Wayland compositor, which can only begin compositing once the scene is done rendering. Even more, the Wayland compositor has to queue a page flip on the display controller so it can show the new frame, but that can only happen once the frame is done rendering!

All of those things have to happen in the right order for everything to work right, and the UAPI must provide a mechanism for it. As graphics APIs have changed over the years, so has the way this is done. Traditionally, UAPIs were based on the OpenGL “implicit sync” model…
Implicit Sync
The implicit sync model is based on the idea that synchronization is tied to buffers, which are things like textures and framebuffers. When work is submitted to the GPU, the kernel driver tracks what buffers it reads from and what buffers it writes to. If it is reading or writing from/to any buffers that are being (or will be) written to by previously submitted GPU work, the driver makes sure that it doesn’t start executing until those jobs are complete. Internally, this works by having each buffer contain one or more DMA fences, which track readers and writers and allow readers to block on prior writers.
This works! It means the app developer doesn’t really have to care about synchronization much: they just render to a texture, then use it later, and the driver makes it look like everything is executing sequentially by tracking the dependency. This works across apps too, and even between the GPU and the display controller.
Unfortunately, this model is not very efficient. It means that the kernel needs to keep track of every single GPU buffer that all render jobs might use! Say a game uses 100 textures: that means that every single time it renders a scene, the kernel has to check to make sure nobody is writing to those textures, and mark them as being read from. But why would anyone be writing to them? After all, most textures are usually loaded into memory once and never touched again. But the kernel doesn’t know that…
This model is supported by all Linux mainline GPU drivers today! Some drivers have since added support for explicit sync (like amdgpu), but they still have support for full implicit sync under the hood. Remember the UAPI stability rules…?
Explicit Sync
Then along came Vulkan, and said there was a better way. In Vulkan, there is no implicit synchronization of buffers. Instead, the app developer is responsible for manually keeping track of dependencies between things they submit to the GPU, and Vulkan provides several tools to tell the system what it needs: barriers, events, fences, and timeline semaphores.
Vulkan is pretty complicated, so we won’t go into all the details… but essentially, these tools give the app fine-grained control over what has to wait for what and when. There is no implicit buffer synchronization any more, which is great! The kernel driver no longer needs to keep track of possibly dozens or hundreds of buffers, but instead only the very specific sync requirements that the app requests.
(By the way, Metal supports both explicit sync and implicit sync for some reason, but I digress…)
Under the hood, Linux implements explicit sync using a standard mechanism called sync objects. Each sync object is basically a container for a completion, which is actually a DMA fence. If you’ve ever used async programming frameworks, you’ve probably heard of promises. DMA fences are basically the GPU version of a promise! Sync objects are actually originally an OpenGL concept, but they have since been adapted and extended to work with Vulkan’s more complex requirements.
In the explicit sync world, when an app submits GPU work to the kernel, it gives it a list of input sync objects and a list of output sync objects. The kernel driver checks all the input sync objects and registers their fences as dependencies of the GPU work. Then it creates a new (pending) completion fence for the work, and inserts it into the output sync objects (remember, sync objects are containers for a fence, so they can be replaced). The driver then queues the work for execution, and returns immediately to userspace. Then, in the background, the work is only allowed to execute once all dependency fences have been signaled, and it then signals its own completion fence when it’s done. Phew! A nice, clean, and modern kernel UAPI for synchronization!
Except there’s a problem…
Trouble with Windowing Systems
Within a single app, Vulkan lets you take care of synchronization. But what about synchronizing across apps, like when a game sends a frame to a Wayland compositor? This could use sync objects… but Wayland was almost 10 years old by the time Linux sync objects were invented!
Of course, all existing window system integration standards in desktop Linux assume implicit sync. We could add explicit sync to them, but that would break backwards compatibility…
What all existing Linux drivers do is… to just support both. You still give the kernel driver a list of buffers you read/write to and from, and that can exclude things like textures that the driver knows are not shared with any other process. Then the kernel implicitly synchronizes with those buffers, and explicitly synchronizes with the sync objects. That works, but again it makes drivers more complicated…
What we need is a way to bridge between the implicit sync and explicit sync worlds, without having to reinvent the wheel for every driver. Thankfully, the Linux DRM subsystem developers have been hard at work solving this, and just a few months ago we finally had a solution!
Bridging both worlds
Remember how I said that implicit sync works by using DMA fences attached to buffers, and explicit sync works by using DMA fences inside sync objects?
Just a few months before our Asahi driver release last year, on October 2022, Linux 6.0 was released. And with it came two new generic DRM APIs: one to import a DMA fence into a DMA-BUF, and one to export it out of it.
Together with the existing generic sync object APIs, this lets us close the gap entirely! Userspace apps can now take a fence out of a DMA-BUF (a buffer shared with another process), turn it into a sync object for a GPU job to wait on, then take an output sync object for that job, and insert its fence into another DMA-BUF that can be shared with another process.
Faith Ekstrand wrote an excellent article covering this if you want more details! She has also been an amazing mentor and I couldn’t have figured out all this UAPI design stuff without her help.
Great! This solves all our problems! But as they say, the devil is in the details…
OpenGL wants a word with you…
Explicit sync is great and all, but we don’t have a Vulkan driver yet, we have an OpenGL driver. How do we make that work?
OpenGL is very much based on the implicit sync model. So to make an OpenGL driver work with an explicit sync UAPI, the driver has to take care of bridging between both worlds. Of course, we could go back to importing/exporting fences on every single buffer, but that would be even slower than doing implicit sync in the kernel in the first place…
There’s also an even bigger problem: Even ignoring buffer sync issues, in an implicit sync world the kernel keeps track of all buffers needed by the GPU. But in an explicit sync world that doesn’t happen! What this means is that an app could render using a texture, then free and destroy the texture… and in an explicit sync driver, that would mean that the texture is deallocated immediately, even if the GPU is still using it! In Vulkan that would be an app bug, but in OpenGL that has to work…
Explicit sync in Mesa has mostly been used for Vulkan drivers, but since pure explicit sync Linux GPU drivers don’t exist in mainline yet, there are no OpenGL (Gallium) drivers in Mesa that do this! They mostly just use the legacy implicit sync path… so I had no code to reference and I had to figure out how to make this work all on my own ^^;;.
And so I set out to find a way to make explicit sync work with the Mesa driver that Alyssa and I had been working on. Thankfully, it turned out not to be too much of a refactor!
You see, in order to have good performance on tile-based mobile GPUs, you can’t just map OpenGL directly to the hardware. On tile-based GPUs, things aren’t rendered directly into framebuffers immediately. Instead, a whole scene of geometry is collected first, then it runs through vertex shaders, gets split up into tiles based on screen position, and is finally rendered tile by tile in super fast tile memory before being written out to the framebuffer. If you split up your rendering into many tiny passes, that means loading and saving the framebuffer every time, and that is very slow on these GPUs! But OpenGL lets apps switch around framebuffers as often as they want, and many apps and games do this all the time… if we just flushed the rendering every time that happened, that would be very slow!
So, to deal with this, Alyssa developed a batch tracking system for the Panfrost driver (based on Rob Clark’s original implementation for Freedreno), and later added a similar system to the Asahi driver. The idea is that instead of sending work to the GPU immediately, you collect it into a batch. If the app switches to another framebuffer, you leave the batch as-is, and create a new batch. If the app switches back to the original framebuffer, you just switch batches again and keep appending work to the original batch. Then, when you actually need to render everything, you submit the complete batches to the hardware.
Of course, there’s an issue here… what if the app is trying to read from a framebuffer it previously rendered to? If we haven’t submitted that batch yet, it will get the wrong data… so the batch tracking system keeps track of readers and writers for each buffer, and then flushes batches to the GPU any time their output is needed for the current batch.
… wait a minute, doesn’t that kinda sound like implicit sync all over again?
It turns out the driver already had all the core bits and pieces I needed! Batch tracking can:
- Track multiple bits of GPU work that are independent at the same time, and
- Track their dependencies based on buffers read/written, and
- Keep buffers they need alive until the batch is submitted to the GPU
I just had to extend the batch tracking system so that, instead of only tracking GPU work that hasn’t been submitted, it also tracks work which has been submitted to the kernel but hasn’t completed yet! Then the existing reader/writer machinery could be used to figure out what buffers are read and written. Since batches are submitted to the GPU in a single queue and execute in order, we mostly don’t have to worry about synchronizing between batches as long as we add a full GPU barrier before each batch.
This ended up being a medium size, but not too unwieldy commit. Most of the changes were in the batch tracking code, and it was mostly just extending the existing code to handle the idea of batches that aren’t active but rather submitted. Then we use the existing Linux sync object APIs to figure out when batches are actually complete, and only then finally clean up the batches. And with that, explicit sync worked!
Well… kind of. It worked for surfaceless (offscreen) render tests, but we still had that pesky issue of how to handle implicit sync for buffers shared with other apps…
Implicit sync’s many sharp edges…
There actually is one driver I could reference. While it is not merged yet, Intel’s new Xe kernel driver is also a brand new, pure explicit sync driver, and the Mesa side adds support for it to the existing Intel Iris driver in Mesa. In fact, the Asahi driver’s UAPI is heavily inspired by the Xe one (at Faith’s suggestion)!
The way these two GPUs work and how the drivers are designed is too different to use Xe/Iris as an example for how to make the internal batch tracking work with explicit sync within the driver, but we can at least take a look at how it handles implicit sync with shared buffers. The idea turned out to be pretty simple:
- Before submitting work to the GPU, look through all the buffers used and find any shared ones, then grab their DMA fences and set them up as input sync objects.
- After submitting work, take the output sync object, extract its fence, and install it into all shared buffers again.
Et voilà! Implicit sync window system integration support!
And then Firefox started crashing on WebGL tests…
Schrödinger’s Buffer Sharing
As part of the new UAPI design, the driver is supposed to tell the kernel when buffers might be shared. The kernel still needs to know about all buffers that an app has allocated, and due to corner cases in memory management (that aren’t even implemented yet in our driver, but will be), still needs to lock them when you do stuff with the GPU. So on existing drivers like i915 you end up with the kernel locking possibly thousands of buffers when GPU work is sent, even if they aren’t all used by the GPU! This is bad, so the Xe UAPI has an optimization that I carried over to Asahi: if you mark a buffer as not shared, the kernel groups it with all the other non-shared buffers and they share the same lock. That means that you can never ever share those buffers between processes, and the kernel prevents this. The Gallium driver layer in Mesa has a flag for whether buffers are potentially shared that gets passed in at creation time, so that’s easy, right?
Except this is legal in OpenGL:
glTexStorage2D(...)(Make a texture, allocate storage, upload data)eglCreateImageKHR(...)(Turn the texture into an EGL image)eglExportDMABUFImageMESA(...)(Export it)
There is no way for the OpenGL driver to know that you’re going to share a texture at creation time. It looks like it’s not shared, and then it’s suddenly shared. Oops!
It turns out this was an existing problem in Mesa for other reasons unrelated to explicit sync, and there is a Gallium callback called flush_resource where drivers are supposed to make resources shareable. So I added some code there to re-allocate and copy the buffer as shareable. It’s not the fastest solution, and we might change it in the future, but it works for now…
All done, right?
21:05 <alyssa> lina: still have magenta rectangles in supertuxkart with latest branches
21:20 <jannau> still at startup in one of two starts? was fine in the stream under plasma/wayland
21:21 <alyssa> yes
21:22 <alyssa> in sway if it matters
21:22 <alyssa> also saw it sometimes in nautilus
21:23 <alyssa> right, can't reproduce in gnome
21:23 <alyssa> but can reproduce easily in sway
21:23 <alyssa> so ... more WSI junk
21:23 <alyssa> and yeah goes away with ASAHI_MESA_DEBUG=sync
21:24 <alyssa> so... some WSI sync issue that only reproduces with sway
21:24 <alyssa> and supertuxkart is the easiest reproduce
03:20 <lina> alyssa: Only on startup and only on sway? Hmm... that's starting to sound like something that shouldn't block release at this point ^^;;
03:20 <lina> Does it go away with ASAHI_MESA_DEBUG=sync only for stk, or for all of sway?
03:26 <alyssa> lina: setting =sync for stk but not sway is enough
03:27 <alyssa> but it's not just supertuxkart that's broken, it's everything, this is just the easiest reproducer
03:27 <alyssa> so yes, this is a regression and absolutely does block release
Schrödinger’s Buffer Sharing, Part 2…
Long story short, it turns out that apps can also do this:
- Create a framebuffer (possibly shareable), but don’t share it yet.
- Render stuff into the buffer.
- Share it.
When we submit the rendering command, it doesn’t look like it’s shared yet, so the driver doesn’t do the implicit sync dance… and then when the app shares it, it’s too late, and it doesn’t have the right fence attached to it. Whoever is on the other side will try to use the buffer, and won’t wait until the render is complete. Whoops!
I had to add a mechanism that keeps track of sync object IDs for all submitted but not complete batches, and attaches them to all buffers that are written. Then if those buffers are shared before we know those batches are complete, we can retroactively attach the fences.
Interestingly, when I brought this up with the Intel folks working on the Xe merge request… they hadn’t heard of this before! It looks like their driver might have the same bug… I guess they might want to start testing with Sway ^^;;
Are we done yet? Mostly, though there are still bugs to squash… and we haven’t even talked about the kernel yet!
Explicit Sync Meets Rust
The previous version of the Asahi DRM kernel driver was pretty bare-bones in how it interacted with the rest of the kernel, since it had a very simple UAPI. I only had to add Rust abstractions for these DRM APIs:
drvanddevice, the core of DRM drivers and handling devices.file, which is how DRM drivers interact with userspace.gem, which manages memory for GPUs with unified memory.mm, a generic memory range allocator which my driver uses for several things.ioctl, just some wrappers to calculate DRM ioctl numbers for the UAPI.
To add proper explicit sync support, I had to add a bunch of new abstractions!
dma_fence, the core Linux DMA fence mechanism.syncobj, DRM’s sync object API.sched, which is the DRM component in charge of actually queuing GPU work and scheduling it.xarray, a generic kernel data structure that is basically anint→void *mapping, which I use to keep track of userspace UAPI objects like VMs and queues by their unique ID.
I’ve now sent out all the DRM abstractions for initial review, so we can get them upstream as soon as possible and, after that, upstream the driver itself!
As part of this work, I even found two memory safety bugs in the DRM scheduler component that were causing kernel oopses for Alyssa and other developers, so the Rust driver work also benefits other kernel drivers that use this shared code! Meanwhile, I still haven’t gotten any reports of kernel oopses due to bugs in the Rust code at all~ ✨
Even more stuff!
Explicit sync is the biggest change for this release, but there’s even more! Since we want to get the UAPI as close as possible to the final version, I’ve been working on adding lots more stuff:
- Multiple GPU VMs (virtual memory address spaces) and GEM object binding based on the Xe UAPI model, to support future Vulkan requirements.
- A result buffer, so the kernel driver can send GPU job execution results back to Mesa. This includes things like statistics and timings, but also whether the command succeeded and detailed fault information, so you can get verbose fault decoding right in Mesa!
- Compute job support, to run compute shaders. We’re still working on the Mesa side of this, but it should be enough to pass most tests and eventually add OpenCL support with Rusticl!
- The ability to submit multiple GPU jobs at once, and specify their dependencies directly, without using sync objects. This allows the GPU firmware to autonomously execute everything, which is a lot more efficient than going through the DRM scheduler every time. The Gallium driver doesn’t use this yet, but it probably will in the future, and our upcoming Vulkan driver definitely will! There are a lot of subtleties around how all the queuing stuff works…
- Stub support for blit commands. We don’t know how these work yet, but at least we have some skeleton support in the UAPI.
To make all this work on the driver side, I ended up refactoring the workqueue code and adding a whole new queue module which adds all the infrastructure to use sync objects to track command dependencies and completions and manage work via the DRM scheduler. Phew!
Conclusions
So what does this all mean for users of the Asahi Linux reference distro today? It means… things are way faster!
Since the Mesa driver no longer serializes GPU and CPU work, performance has improved a ton. Now we can run Xonotic at over 800 FPS, which is faster than macOS on the same hardware (M2 MacBook Air) at around 600*! This proves that open source reverse engineered GPU drivers really have the power to beat Apple’s drivers in real-world scenarios!
Not only that, our driver passes 100% of the dEQP-GLES2 and dEQP-EGL conformance tests, which is better OpenGL conformance than macOS for that version. But we’re not stopping there of course, with full GLES 3.0 and 3.1 support well underway thanks to Alyssa’s tireless efforts! You can follow the driver’s feature support progress over at the Mesa Matrix. There have been many, many other improvements over the past few months, and we hope you find things working better and more smoothly across the board!
Of course, there are lots of new corner cases we can hit now that we have support for implicit sync with an explicit sync driver. We already know of at least one minor regression (brief magenta squares for a couple of frames when KDE starts up), and there’s probably more, so please report any issues on the GitHub tracker bug! The more issue reports we get, especially if they come with easy ways to reproduce the problem, the easier it is for us to debug these problems and fix them ^^.
* Please don’t take the exact number too seriously, as there are other differences too (Xonotic runs under Rosetta on macOS, but it was also rendering at a lower resolution there due to being a non-Retina app). The point is that the results are in the same league, and we will only keep improving our driver going forward!
Get it!
If you’re already using the GPU drivers, just update your system and reboot to get the new version! Keep in mind that since the UAPI changed (a lot), apps will probably stop launching or will launch with software rendering until you reboot.
If you still haven’t tried the new drivers, just install the packages:
$ sudo pacman -Syu
$ sudo pacman -S linux-asahi-edge mesa-asahi-edge
$ sudo update-grub
Then if you’re using KDE, make sure you have the Wayland session installed too:
$ sudo pacman -S plasma-wayland-session
After that, just reboot and make sure to choose a Wayland session on the login window! Remember that if you are switching from Xorg you will probably have to re-configure your display scale in the KDE settings, since KDE will think you’ve switched monitors. 150% is usually a good choice for laptops, and don’t forget to log out and back in for the changes to fully take effect!
What’s next?
With the UAPI shaping up and many native ARM64 Linux games working properly… it’s time to see just what we can run with the driver! OpenGL 3.x support, while not complete, is more than enough to run many games (like Darwinia and SuperTuxKart’s advanced renderer). But most games are not available for ARM64 Linux so… it’s time for FEX!
FEX doesn’t work on standard Asahi Linux kernel builds since we use 16K pages, but 4K page support is not actually that difficult to add… so starting this week, I’m going to be adding 4K support to the Asahi GPU driver and fixing whatever issues I run into along the way, and then we’re going to try running Steam and Proton on it! Let’s see just how much of the Steam game library we can already run with the driver in its current state! I bet you’ll be surprised… (Remember Portal 2? It only requires OpenGL 2.1. With 3.x support in our driver as far as it is today, I bet we’re going to have a lot of fun~ ✨)
If you’re interested in following my work, you can follow me at @lina@vt.social or subscribe to my YouTube channel! I stream my work on the Asahi GPU driver on Wednesdays and Fridays, so feel free to drop by my streams if you’re interested!
If you want to support my work, you can donate to marcan’s Asahi Linux support fund on GitHub Sponsors or Patreon, which helps me out too! And if you’re looking forward to a Vulkan driver, check out Ella’s GitHub Sponsors page! Alyssa doesn’t take donations herself, but she’d love it if you donate to a charity like the Software Freedom Conservancy instead. (Although maybe one day I’ll convince her to let me buy her an M2… ^^;;)