Progress Report: January / February 2021
Welcome to the first Asahi Linux Progress Report! In this series we’ll be taking a page from the Dolphin playbook and giving you monthly updates on the progress of the project.
Bringing up support for a new system-on-chip on Linux is no small task! I hope this series will be educational to everyone and give you a glimpse of the behind-the-scenes work that goes into making Linux work on a brand new device. The original plan was to do separate updates for January and February, but things were moving so fast it was hard to call a cut-off point, so we ended up with a two-month update.
Quick terminology note
In this report, you will see the terms AArch64, ARM64, and ARMv8-A. AArch64 refers to the 64-bit ARM architecture instruction set; ARM64 is what Linux calls its support for 64-bit ARM; and ARMv8-A is the ARM CPU architecture specification that includes AArch64. The terms have subtly different meanings, but for our purposes you can mostly take them all to mean “64-bit ARM”.
Where it all starts
The Asahi Linux project officially kicked off at the beginning of the year, but at that time we were all waiting for one crucial piece: support from Apple for booting alternate kernels on Apple Silicon systems. While the feature had been documented and mostly implemented, there was one final missing piece of the puzzle: support for the kmutil configure-boot command, which is what lets you install a non-Apple kernel. This didn’t stop us from making progress, however, as the first step to porting an OS to an undocumented platform is documenting it!
Apple Silicon Macs boot in a completely different way from PCs. The way they work is more akin to embedded platforms (like Android phones, or, of course, iOS devices), but with quite a few bespoke mechanisms thrown in. However, Apple has taken a few steps to make this boot process feel closer to that of an Intel Mac, so there has been a lot of confusion around how things actually work. For example, did you know that Apple Silicon Macs cannot boot from external storage at all, in the traditional sense? Or that the bootloader on Apple Silicon Macs cannot show a graphical user interface at all, and that the “Boot Picker” is in fact a full-screen macOS app, not part of the bootloader?
And so, before we were able to run our own kernels on these machines, we set out to map out how the boot process works, how partitions and volumes are laid out on the internal SSD, and also how this all compares to a PC. This documentation is intended to not only be useful for our project, but also for any macOS users who want to better understand how their machines work. Some of the functionality and the underlying rationale for it (but not all) has since been documented in the February 2021 version of the Apple Platform Security Guide.
Bridging two worlds
Apple Silicon Macs have a boot process that is not based on any existing standard. Rather, it is a bespoke Apple mechanism that has slowly evolved from the early days of iOS devices. On the other hand, the rest of the 64-bit ARM world has largely converged on two competing standards: UEFI + ACPI (largely used by servers running Windows or Linux), and the ARM64 Linux boot protocol + DeviceTree (used on smaller systems, and also supported by U-Boot and more). We need to choose one of these for Asahi Linux and figure out a way to “bridge” Apple’s world to our own.
UEFI and ACPI are complicated beasts usually only used for large ARM systems. The standards are largely controlled by committees at the UEFI Forum. Unlike the x86 PC world, which is much more homogeneous, the ARM world is extremely diverse and systems-on-chip have all kinds of designs with different requirements for describing the hardware contained within them. This means that adding support for a new SoC almost always requires amending these standards to add “bindings” for the bits of hardware that make it unique. For ACPI, this is costly and slow, which is why ACPI is almost never used on small embedded systems that don’t run Windows. It is not a viable option for us.
The wide variety of smaller embedded ARM Linux systems almost invariably use the DeviceTree standard – for example, this is how most Android devices boot. Devicetrees are much simpler than ACPI, since a devicetree is purely a bunch of data describing the hardware, while ACPI tables are a combination of data and code. These days, the authority on devicetree bindings is the documentation maintained inside the Linux kernel tree itself: this means that we can amend these standards at the same time as we write the Linux drivers themselves. Thus, Asahi Linux’s boot process will use this model.
Interestingly enough, Apple also uses their own version of a device tree on Apple Silicon, called Apple Device Tree! This is because both it and the open DeviceTree standard are based on the Open Firmware specification, which is how many PowerPC systems boot, including older Macs. Unfortunately, while this does mean ADTs are very familiar to any embedded Linux developer, we cannot use them directly: the binary format is different and cannot be converted automatically without having high-level information about what the data represents. On top of that, the actual bindings used for devices are very different. While Linux and macOS work the same way on PowerPC Macs and are directly compatible, Linux has seen over a decade of divergent evolution from Apple in the ARM space. Trying to unify Apple’s and Linux’s ideas of how device trees should work would be a nightmare.
To adapt the Apple world into a devicetree world, we are developing m1n1, a bootloader for Apple Silicon machines. Its goal is to take care of as many “Apple-isms” as possible, to make life as easy as possible for Linux or anything else downstream.
You can prepend m1n1 to a Linux kernel (just using cat m1n1.macho initrd.bin devicetree.dtb Image.gz > m1n1-kernel.macho works for a minimal fixed-kernel install), install it on your Mac using Apple’s kmutil tool, and it will do everything required to make Linux boot. When you boot Linux using m1n1, this is roughly what it does:
- Initializes the main CPU, and applies chicken bit settings to make it work correctly.
- Reads the boot information that Apple’s bootloader, iBoot, has provided to it: this includes things like how much RAM is available and the address of the framebuffer (the video memory being displayed on the screen) in RAM.
- Initializes the Memory management unit. This is required to be able to use the CPU caches, without which everything runs extremely slowly.
- Puts the Asahi Linux logo on the screen, which replaces the Apple logo.
- Disables the watchdog timer. Without this, the Mac will spontaneously reboot after a minute or so, as it thinks the boot process has gotten stuck.
- Figures out what it is going to boot: the Linux kernel, devicetree, and (optionally) the initramfs ramdisk containing boot-time applications, if they were appended to it.
- Initializes all the other CPU cores and applies the required chicken bits, then sets them up waiting in a “spin-table”, ready for Linux to take over.
- Takes information from the Apple Device Tree and customizes the provided devicetree template to match. This is used for settings that change from machine to machine and from version to version of Apple’s iBoot firmware, such as memory size, information about the framebuffer, a seed to initialize Linux’s random number generator, and more. m1n1 also adds some information of its own, such as the spin-table details and command-line arguments for the kernel, if any.
- Jumps to Linux, or whatever the next stage is.
The “spin-table” is one of two standards that Linux on ARM can use to turn on additional CPU cores in a devicetree world. Instead of relying on platform-specific drivers, there are two standard methods available that all platforms are expected to use. Spin-tables, which are the simplest one, just have the bootloader turn on all CPUs ahead of time and leave them waiting (“spinning”) in a loop. To release the CPUs from the loop, Linux writes a value to RAM telling them where to jump into the kernel. This is perfectly fine for simple platforms; the only real limitation is that CPUs cannot be completely stopped again, as taking over the CPUs from the bootloader is a one-shot deal. However, they can be put into various low-power modes using other mechanisms. We are using this method for now, and it is possible it is all we will ever need.
The alternative is called “PSCI”, and it is an ARM standard that is designed as a proper service that a system’s firmware can provide even while Linux is running, to allow the CPUs (and other components) to be controlled at runtime. Normally, this is done via code running at “EL3” (that’s the secure firmware, or TrustZone), or via a VM hypervisor running at “EL2” – OSes normally run at EL1. However, both EL3 and EL2 are optional features of ARMv8-A CPUs – and as it turns out, there is no EL3 support on the M1. EL2 is available, but we want to support VMs running under Linux, which requires running Linux itself as EL2 – so we can’t put another hypervisor above it. This means we can’t use PSCI today, because there is no standard interface for PSCI that works for us. In the near future, alternative mechanisms may be developed that allow us to use it. This might be necessary to support full-system sleep mode – though, if fine-grained power management is good enough, we might not need “true” full-system sleep to get very good battery life anyway (modern devices work very well with finer-grained sleep modes). Time will tell, and this is still an evolving area.
Now, I said that we would be using devicetree – but that doesn’t mean we can’t use UEFI! ARM64 systems can boot using UEFI + devicetree, and this is needed to get a “PC-like” boot experience, with bootloaders such as GRUB and the typical flows for installing and upgrading kernels. But m1n1 does not support any of that, so what do we do? Thankfully, there is another piece that completes the puzzle: U-Boot. U-Boot can boot like a Linux kernel – so you can boot U-Boot from m1n1 – and it itself can provide a good enough UEFI environment for GRUB and Linux.
And so, most likely, the boot chain for Asahi Linux as used by end-users will be:
m1n1 → U-Boot → GRUB → Linux
Combined with the Apple-specific bits of the boot chain, the entire boot process ends up looking like this:
- The SecureROM inside the M1 SoC starts up on cold boot, and loads iBoot1 from NOR flash
- iBoot1 reads the boot configuration in the internal SSD, validates the system boot policy, and chooses an “OS” to boot – for us, Asahi Linux / m1n1 will look like an OS partition to iBoot1.
- iBoot2, which is the “OS loader” and needs to reside in the OS partition being booted to, loads firmware for internal devices, sets up the Apple Device Tree, and boots a Mach-O kernel (or in our case, m1n1).
- m1n1 parses the ADT, sets up more devices and makes things Linux-like, sets up an FDT (Flattened Device Tree, the binary devicetree format), then boots U-Boot.
- U-Boot, which will have drivers for the internal SSD, reads its configuration and the next stage, and provides UEFI services – including forwarding the devicetree from m1n1.
- GRUB, booting as a standard UEFI application from a disk partition, works like GRUB on any PC. This is what allows distributions to manage kernels the way we are used to, with
grub-mkconfigand/etc/default/gruband friends. - Finally, the Linux kernel is booted, with the devicetree that was passed all the way from m1n1 providing it with the information it needs to work.
Phew! This might look a bit crazy to people coming from the PC world, but long boot chains like this are common on embedded systems (and in fact, “UEFI” on a typical PC includes multiple stages, it’s just that end-users don’t see them). For example, one possible boot chain for a DragonBoard 410c (a Qualcomm-based platform) might look like this:
PBL → SBL → QSEE → QHEE → LK → U-Boot → GRUB → Linux
Note that we cannot replace iBoot2 (it requires an Apple signature), but our end-user install process will deal with automatically setting up a minimal “macOS” including iBoot2 and all the required support files, sufficient for the Apple boot process to recognize it as a bootable OS (but excluding the actual macOS kernel/filesystem). The installer isn’t ready yet, so for the time being developers experimenting with m1n1/Linux have to make a separate full macOS install and then replace its kernel. We’ve written a step-by-step Quick Start Guide to guide those wanting to join us in this adventure.
Right now, our main development workflow is to load Linux directly from m1n1, but Mark Kettenis is working with us on U-Boot and OpenBSD support.
But m1n1 isn’t just about running Linux. In fact, it isn’t even a bootloader at heart!
Playing with hardware
m1n1 traces its past to mini, which is a minimal environment that I wrote for the Nintendo Wii’s security CPU. It was useful for experimentation and as the back-end for BootMii – for those of you who own a Wii and are familiar with it, mini is what runs on the ARM CPU while you’re in the BootMii menu.
What does that have to do with an Apple Silicon bootloader, you ask? Well, mini was really just a very simple piece of software that runs on bare-metal 32-bit ARM systems without any external libraries or dependencies. It makes for a nice, simple base on which to build bare-metal code, so we ported it to AArch64 and Apple Silicon and renamed it to m1n1. But more importantly, mini and m1n1 have a trick up their sleeves: thanks to mini’s legacy as firmware running on a separate processor that needs to be controlled from the main CPU, and from past experiments with Wii hardware research, it has a built-in RPC proxy that works over a serial port. This means that you can “remote control” mini and m1n1 from a development computer, in real time. m1n1 lets you play with the M1 hardware using simple Python scripts running on any computer, or even from an interactive shell. It would be best described as a hardware experimentation tool that just happens to also feature a Linux bootloader.
This makes for an awesome platform to learn more about the hardware and discover all of Apple’s proprietary features. For example, this script tests a special Apple feature that adds support for a some x86-specific floating point configuration bits to their CPUs, which they use to speed up Rosetta x86 emulation. This script searches for all Apple-custom CPU registers and prints their values and their access restrictions. This script automatically figures out how those access restrictions can be customized by an Apple-proprietary hypervisor configuration register. And, of course, this script will boot a Linux kernel for you, streamed in straight from the serial port.
Booting an M1 Mac Mini into m1n1 takes about 7 seconds, and all of these scripts can be run interactively without rebooting (until you crash the machine). m1n1 can also load itself, so the development cycle for m1n1 itself is also very fast: you can leave an old version of m1n1 installed with kmutil and simply load the most recent one at runtime after a reboot.
Using m1n1, we’ve been hard at work documenting Apple’s custom ARM instructions, Apple-specific system registers, hardware such as the Apple Interrupt Controller, and more.
In the future, we will keep adding features to m1n1 to make it an even more powerful research tool. One particularly exciting goal is to turn it into a very thin VM hypervisor that can boot macOS, and intercept its accesses to the M1 hardware. This will allow us to investigate how Apple’s drivers work without having to disassemble them, which makes for a very legally-sound approach, and is also quite a lot more efficient than tracing through complex proprietary driver code. Some of you might recognize this approach as the same one used by nouveau to successfully reverse engineer Nvidia GPUs – though in that case, they used the Linux drivers and modified the kernel only, instead of adding a hypervisor.
But wait – to do all this you need a serial port. Where’s the serial port on M1 Macs? I’m glad you asked!
There You Are, UART!
To do low-level bring-up work on a new system, it is almost indispensable to have a serial port. Serial ports, sometimes called UART ports, are practically the simplest possible communications hardware, and make for a very convenient low-level debugging tool. Sending messages over a serial port only requires a couple of CPU instructions, so it can be set up very early, and serve as a text terminal for development.
Of course, modern PCs used to have RS-232 serial ports, but those are long gone. On many embedded systems (such as most home routers), a lower-voltage serial port still exists internally, but you need to remove the case to access it on a connector, or as test points directly on the board. What about M1 Macs?
It turns out that M1 Macs do in fact have a serial port accessible on the outside of the case – over one of the USB-C ports! However, to enable it, you need to send some special commands over USB-PD. USB-PD (USB Power Delivery) is a protocol that runs over the “Configuration Channel” pin on Type C ports. As usual for USB standards, it is an overengineered behemoth that does a lot more than actually delivering power – not only is it used to configure voltages and identify chargers, but it’s also used to identify cable types, dongles, alternate modes such as DisplayPort, and, in this case, as a channel for Apple-proprietary configuration messages. These messages let us ask a Mac to expose its serial port on two pins of one particular Type C port. Other neat features include the ability to reboot the system remotely (indispensable for fast development), put it into DFU recovery mode, access internal buses such as I²C, and more.
Our first solution to getting a serial port working on these Macs was vdmtool: a DIY cable using an Arduino, a USB-PD PHY (interface) chip, and some kind of 1.2V serial port adapter. This is fine for those with DIY skills, but it is not very practical for those who are not used to building their own hardware. There are a number of annoyances: there are no good USB-PD PHY break-out boards with all the required Type C signals, 1.2V UART adapters are rare, etc.
Therefore, we came up with a second solution: if you happen to have two M1 Macs, rejoice! All you need is a standard Type C cable (the SuperSpeed / USB 3.0 type) and macvdmtool. This little macOS app lets you turn one M1 machine into a serial debug terminal for another, so you can run m1n1 scripts and boot Linux kernels directly from macOS. Apple’s APIs allow us to configure a Mac’s own port into serial mode, as well as send the required messages to configure the remote Mac into serial mode too, which makes all of this possible with no custom hardware whatsoever.
But of course, another Mac makes for quite an expensive serial cable! Therefore, we will be developing a much more fully-featured USB-PD debug cable as an open hardware project, useful not only as a serial adapter for M1 Macs, but also to expose the other special features. In fact, it will go beyond Macs and also work as a debug interface for other devices, such as many Android phones. It will also work as a USB-PD development platform, capable of acting as a generic source (power supply) or sink (power consumer) and more, to experiment with USB-PD chargers and devices. It’s still in the planning stages, but stay tuned for updates! Our goal is to eventually make this widely available to the community, so anyone can just click a button and buy one.
Finally, although a hardware serial port is the best solution for low-level debugging and development, it has limitations: it is quite slow, topping out at 150 kB/s. M1 Macs, however, can also behave as normal USB devices (like an iPhone, for example), and we can make them show up as a USB-serial device (CDC-ACM) that works without drivers on most OSes. This gives us the full bandwidth of USB, and the convenience of being able to use a normal Type C cable (or Type C to Type A cable) to just connect from any other computer. USB also provides flow control, which means that no data is lost when the receiving side is not ready to accept more data. The downside of this approach is that it requires much more complex driver code, so it is not suitable for figuring out really low-level issues. But once this is supported in m1n1, it will be more than enough for most of the remaining work, and we can comfortably develop this more complex driver code using the existing serial port support: the Type C port on these Macs can support both UART serial and USB signals at the same time. The extra bandwidth and performance will be very helpful once we start working on the hypervisor mentioned above, and will also make loading Linux kernels much speedier, as that is currently bottlenecked on serial bandwidth. This support is likely to come to m1n1 in the following weeks, so stay tuned!
The Road to Penguins
All of these tools are well and good, but our goal is to run Linux after all. So, how does one port Linux to a brand new platform? Of course, a large part of the overall process involves writing new drivers, but there is a specific set of things that need to be done first. We call this “bring-up”.
Bring-up is very important not just because it lays the foundation for the rest of the OS to work on the machine, but also because it means setting the standards for how machine-specific features work. This is low-level code that ties in with some of the deepest parts of the OS, and unlike typical drivers, often requires making changes to parts of Linux that are common to other platforms. This requires coordinating with the Linux maintainers responsible for those subsystems, and agreeing on the right way to approach these challenges.
To give you an idea of how deep the rabbit hole goes: as part of our initial M1 support patch set, we had to make a change to a file related to support for the SPARC64 architecture! One unique feature of Linux development is that the Linux kernel does not have a stable driver API/ABI, which means that the internal design of the Linux kernel is subject to continuous improvement and refactoring over time. That means that if supporting something on one architecture warrants cleaning up or changing other architectures, doing so is perfectly feasible, and often the best way to do things. However, it also means that it is very difficult to maintain Linux forks, or third-party drivers that are not part of the upstream kernel.
At Asahi Linux, our goal is not just to port Linux to Apple Silicon, but to do so as an open community-driven project, working together with the overall Linux community to upstream our work into the official Linux kernel. This is rare in the embedded ARM space, because most companies developing Linux ports for their hardware do so on product development deadlines; instead, they end up creating a Linux fork and doing all of their development there, detached from the upstream community. By the time they decide to upstream their changes into the official Linux kernel, if they do so at all, the two forks have usually diverged so much that merging becomes a nightmare. The design decisions that were taken may also run counter to the overall Linux philosophy, and not be acceptable upstream. In the end, a lot of the code ends up being rewritten, and a lot of development time is wasted due to the pursuit of short-term results over long-term sustainability.
We absolutely do not want to end up in this scenario, so our approach is to upstream early, and work with the overall community from day 1. To this end, we have been working with the upstream Linux maintainers, and in fact several key Linux folks now hang around in the Asahi Linux IRC channels!
To get Linux to boot on any system at all, there are five pieces that absolutely need to work properly:
- The CPU
- The memory management unit (MMU)
- The interrupt controller
- The system timer
- Some kind of console – in this case, a serial console
On most AArch64 systems, the first four are quite standard: Linux needs practically no changes to run to the point of getting a basic console. Alas, Apple SoCs like to do things their own way… so we had quite a bit of work ahead!
Turn It Off And On Again
Modern CPUs are an engineering marvel compared to designs from the 80s and 90s. Back then, a CPU’s job was really just to perform simple arithmetic, read and write memory, and make decisions – one by one, in sequence, never stopping. There was no power management, no caching, no multi-core, and barely even support for floating-point numbers.
Times have changed, and today CPUs have become more and more powerful while also using less and less power. How do they achieve this? Part of it is, of course, thanks to improvements in IC manufacturing. The other half is thanks to vast advances in CPU design. Single CPU cores these days can run multiple instructions at once, predict the future to get things done ahead of time, roll things back if the prediction was wrong, keep around copies of recently used data or data predicted to be used soon, and even dynamically turn parts of themselves on and off to save power.
With all this complexity, however, comes two problems: unexpected features, and outright bugs. OSes these days need to be much more involved with micro-managing these details of the CPUs they run on, and even application software needs to take care not to make assumptions that the CPU is allowed to break.
Those old enough to have used computers in the 90s may remember a peculiarity of Windows 95 and Windows 98. When using those OSes on new (at the time) computers, the CPU temperature would rise quite a bit – and stay high, no matter how little you were using the computer. The reason for this is that these operating systems, when given nothing to do, simply had the CPU running in an endless loop. Even when doing nothing, 100% of the CPU was “in use”, all the time! On older CPUs there was no concept of an “idle” CPU: if you weren’t using it to do useful work, you were using it to waste time. There was no power management, so no power was saved if you told the CPU to do nothing for a while.
Of course, today we are all used to the idea that an idle CPU somehow saves power over a busy CPU. This works because the OS, when given nothing to do, can instruct the CPU to stop working to some extent, waiting for an event: a signal from the outside world that something needs to be done. On x86 PCs, this is done with the “HLT” (Halt) instruction; in the Windows 95 era, there was a program called “CpuIdle” that ran HLT in an endless loop, putting your CPU into low-power mode when you weren’t using it, saving energy and lowering your CPU temperature. Modern OSes have this built in, and ARM CPUs implement the same mechanism using a CPU instruction called “WFI”, or Wait For Interrupt.
Modern CPUs don’t just stop running instructions when you call HLT or WFI, but can actually power down portions of the core to save even more power. Stopping the clock is called “clock-gating”, and powering down is called “power-gating”. However, there’s a catch: power gating causes the CPU to lose any data kept in the parts that were turned off. Critical data needs to be in circuits that stay powered up, or moved to back-up storage that does. Normally, these instructions don’t cause any visible data loss; the CPU may throw away some data it doesn’t need, but it takes care not to lose data that the software is working on.
When we got to the point where Linux was sort-of booting on the M1, it crashed almost immediately once the boot process was over. In fact, it seemed to crash right after running the WFI instruction: it was jumping to a zero address, instead of returning to the calling function properly. What’s going on?
As it turns out, the M1 by default runs in a mode where WFI can do one of two things: either clock-gate, or power-gate. It actually picks which one to use using some sort of automatic heuristic (fancy!). Unfortunately, when it decides to power-gate, it loses the contents of all CPU registers other than the stack pointer and the program counter. Linux very much does not expect that to happen. This would be a rather nasty patch to add to Linux, since every other AArch64 CPU out there does not do this; Linux has no mechanism for specific SoCs to replace its WFI idle loop with something else. It would be a gross CPU-specific hack in the middle of common Linux code.
Thankfully, thanks to our efforts to document the CPU’s Apple-proprietary registers and working with the chicken bit sequences that are required to make the CPU work properly, we found that there is a specific register that can be used to override this behavior and make WFI never power-gate, thus making Linux work properly. All we had to do is set this register to the correct value in m1n1, and that solved the problem! This is the best kind of fix: m1n1 can take care of the problem, and no Linux patches are necessary.
You may be wondering if this affects the power efficiency of the system. Fear not! This doesn’t mean we cannot make use of the M1’s power-gating capabilities. Linux supports deeper CPU power-saving modes using a subsystem called cpuidle. It’s via this subsystem that Linux expects to put CPUs into deeper power saving modes, and a driver for this subsystem is perfectly entitled to make the CPU lose state, as long as it knows how to recover from it. Therefore, all we need to do is write a cpuidle driver that flips the M1 back into power-gating mode (perhaps even bypassing the heuristic, if Linux’s internal algorithms do a better job), executes a WFI directly in the driver, then restores CPU state before returning back to the core Linux code. CPU power saving, managed the Linux way.
This highlights an important part of our development approach. When working with an undocumented device, it is easy to simply do what the original software (macOS) does. However, the way another OS or firmware works may not necessarily be the best model for Linux. Instead, we prefer to prioritize understanding the finer points of the system, and only then decide the best way to make use of them in Linux. Had we simply done what macOS does (it supports the power gating mode in the main CPU idle loop) instead of investigating the related CPU registers, we would’ve ended up with a messier Linux patch and missed out on the opportunity to do it a cleaner way. This does take more time, but we think the result is worth it!
This wasn’t the only CPU surprise we found while getting Linux up and running, but unfortunately, that story will have to wait for a later time… so let’s move on to the next part: memory management.
Undelivered Post Returned To Sender
When first bringing up Linux, being able to get feedback on the boot process early is critical for debugging (we don’t have hardware debug capabilities – those are not available on production Apple devices). The aforementioned serial port is great for this, as it only takes a couple CPU instructions to send a character: just write it to a register on the UART hardware. Linux has a feature called earlycon that can help with this by making the usual Linux printk() function work before the main serial port driver comes up, but unfortunately, the first tests didn’t even get that far. This situation becomes a game of patching the very earliest ARM64 startup code in Linux (which is written in assembly) to print out characters at specific points, to find out where things break.
It became evident that the serial port worked right up until the point where the memory management unit was turned on. This is a rather unfortunate situation, as the memory management unit changes how accesses to memory work, including accesses to the UART device – but it is very hard to debug such problems, because the MMU is configured and then finally turned on in one shot. If things break then, you have no idea where the problem is.
Yet, during a very long debugging session (which ended up with me adding code to paint the top of the display framebuffer with different colors to indicate progress through the Linux kernel boot, as an alternative feedback mechanism), it became evident that Linux was in fact continuing to boot, past all the assembly code and into running C code, and even into the earlycon serial port driver. But nothing was being sent out the serial port. It’s as if it was just… ignoring everything we threw at it. The address was correct, the memory mapping was correct, but… nothing.
As it turned out, the M1 is… unusually picky about how it handles memory management for devices.
The memory management unit is at the heart of what every modern OS kernel does. It is the part of the CPU that makes possible things like isolating running processes from each other, managing virtual memory (swap files/partitions), mapping files on disk into memory, sharing data between threads and processes, and more. It is in charge of mapping multiple virtual memory address spaces (the idea of memory addresses that applications and the kernel have) to the physical address space (the actual memory addresses of hardware in the system). Here, “memory” includes both actual RAM as well as devices, which appear as memory-mapped I/O (MMIO). The UART is an MMIO device.
On most platforms there is a distinction between normal memory and MMIO. Normal memory (i.e. RAM) can be assumed to behave in certain reasonable ways, such as always returning written data when you read it back later. But devices use MMIO to receive commands and return status and data back to the software, so they don’t behave like normal RAM. The CPU is allowed to re-order and cache normal memory accesses, but if it were to do so for MMIO accesses, everything would break, as drivers rely on precisely controlling when data gets sent to and received from a device. The MMU is in charge of this distinction: the kernel configures bits of memory as normal memory, or as device memory.
But, of course, things are much more complicated than that these days. There are access permissions, there are different caching modes, and there are different kinds of device memory. On AArch64, there are four possible modes for mapping device memory: GRE, nGRE, nGnRE, and nGnRnE. The letters G, R, and E stand for three different things the system is or is not allowed to do:
- Gather multiple writes into a single write. For example, the CPU may turn two adjacent 8-bit writes into a single 16-bit write.
- Re-order writes. If you write two values in sequence to distinct addresses, the CPU may decide to write them in the opposite order.
- Complete writes early. The system may tell the CPU that a write to memory is complete before the data actually makes it all the way to the target device, so it can continue executing code without waiting for that to happen. This is also known as a “posted write” in the x86 world.
Most drivers and devices would break with write-gathering and re-ordering enabled, so those modes are seldom used except by very specific drivers. However, early write completion is actually the standard on PCs, because it is mandated by the PCI specification. Therefore, almost every driver is written to account for this. For this reason, AArch64 Linux also defaults to mapping all I/O memory as nGnRE, with early termination enabled. On other devices, this poses no problem. Many of those devices may not support posted writes as such, but in that case they would simply treat the accesses as nGnRnE. Devices are always allowed to provide stricter guarantees than what the software requests; as long as the device behaves at least as strictly as the software requires, there is no problem.
As we found out, the M1’s internal bus fabric actively enforces that all accesses use nGnRnE mode. If you try to use nGnRE mode, the write is dropped, and instead the system signals an SError (System Error). We were not seeing these SErrors initially due to a CPU configuration setting that had been inadvertently pulled in from another project, which was incorrectly disabling error reporting (though we wouldn’t have been able to see the errors either, since the UART was broken, at least it would’ve caused the system to stop working after UART writes instead of silently dropping them and continuing).
Astute readers might have noticed an interesting detail here: the M1 SoC has PCIe! In fact, some internal devices are PCIe devices (such as Ethernet on the Mac Mini), and, thanks to Thunderbolt, M1 Macs can be connected to any PCIe device. Don’t those use posted writes? Indeed, they do! In fact, the M1 requires nGnRE mappings for PCI devices, rejecting nGnRnE writes.
This poses a conundrum. Linux has no framework for mapping memory as nGnRnE. We could introduce a one-off quirk to use nGnRnE instead of nGnRE mode everywhere, but then that would make it impossible to support PCIe devices which require nGnRE. This became our first real test of upstream interaction: we had to develop a completely bespoke mechanism for mapping memory as nGnRnE, and then a way to instruct Linux to use it for non-PCI devices on Apple Silicon platforms, while still allowing PCI drivers to use nGnRE mode. And we had to do it in a clean, well-engineered way, that balances being non-intrusive to existing code and being potentially useful to other non-Apple devices, and that we could agree on with the maintainers responsible for these subsystems.
In the end, after several weeks of discussion with kernel maintainers across multiple subsystems and multiple patch revisions, we have largely settled on this approach:
- Introducing
ioremap_np(). Linux normally uses the genericioremap()function to map MMIO device memory, across all architectures. There are special variants for other, less strict modes, likeioremap_wt(). We are adding a new variant which specifically requests non-posted memory mappings. - Implementing
ioremap_np()to use nGnRnE mode on ARM64 (other architectures will not implement this variant for now, though they can do so if they find it useful). - Introducing the
nonposted-mmiodevicetree property. This can be used to mark a particular bus in the devicetree as requiringioremap_np(). - Making the Linux device tree subsystem automatically pick up the
nonposted-mmiomode when devices are looked up, and turn it into a flag in the structure describing the MMIO resource (IORESOURCE_MEM_NONPOSTED). - Making two high-level APIs automatically interpret this flag and “upgrade” to an
ioremap_np():devm_ioremap_resource()andof_iomap(). - Adapting existing drivers that we need to use on M1 SoCs to make sure they use one of these APIs, instead of a raw
ioremap(), if they don’t already do so.
This does require some minor driver re-factoring for drivers that use ioremap() directly, but since this is only necessary for hardware that is built into the M1, only a few drivers need to be changed. The vast majority of PCI drivers use a raw ioremap() these days, and all of them could be used with M1 computers via a Thunderbolt adapter; none of those drivers need to be changed, as the default ioremap() will work properly for those by still requesting nGnRE mode.
As part of this change, we also realized that documentation on all the different ioremap() modes in Linux was sorely lacking, as was complete documentation on the I/O read and write functions (which are related, and of which there are many subtle variants). I worked together with Arnd Bergmann to add these missing docs, which you can find here (this will be here once the changes are merged upstream).
Interestingly, since this change applies to the generic “simple-bus” device, it means we had to contribute patches to the core DeviceTree specification and its schemas. Thankfully, as DeviceTree is an open community-driven project, all it takes is a couple GitHub PRs!
You See, It’s AIC
A modern CPU’s job isn’t just to run instructions in order, but also to react to changes in the environment that might require it to stop what it is doing and go do something else. These are often called “exceptions”. You might know these from high-level programming languages as an error of some sort, but in CPUs they are also used to indicate when there is an external need for attention (similar to signals like SIGCHLD and SIGALRM in POSIX userspace programs).
The most important of these is the interrupt request (IRQ), which is used by hardware peripherals to request the attention of the CPU. The CPU then runs some OS code which is in charge of figuring out which peripheral needs attention and handling the request.
On AArch64 CPUs, there is a single IRQ input. That means that something needs to gather together the interrupt requests from all devices in the system, distribute them to the correct CPU cores (as configured by the OS), and tell the OS which underlying devices need attention when an IRQ fires. This is the job of the interrupt controller, or “irqchip” in Linux terminology.
On systems with more than one core, the IRQ controller also has another job: handling inter-processor interrupts (IPIs). Sometimes, software running on one core needs to get the attention of another core. IPIs make this possible: the interrupt controller provides some kind of mechanism where one core can send it a request, which it will then forward as an interrupt to another core. Without IPIs, multi-core systems cannot work properly.
Most AArch64 systems use a standard interrupt controller, called the Generic Interrupt Controller (GIC). This is a rather complex and fairly full-featured interrupt controller, with advanced features such as interrupt priority, virtualization, and more. This is great, because it means Linux does not need to implement proprietary irqchips as the main interrupt controller on most AArch64 systems.
As you’ve probably guessed by now, Apple decided to go their own way. They have their very own, custom Apple Interrupt Controller (AIC). We had to reverse engineer this hardware and build our own irqchip driver for Linux to support it! Thankfully for us, AIC is actually quite simple. By using the few scraps of outdated documentation that exist in the open source portion of macOS/iOS (XNU), and probing the hardware via trial and error, we were able to figure out everything we needed to make interrupts work and write a Linux driver.
Alas, there was one additional wrinkle. Linux needs IPIs to work properly. Specifically, Linux uses 7 different types of IPI: it expects to be able to send 7 different kinds of independent requests from one CPU core to another, and treat them as distinct events. Every other IRQ controller used on AArch64 systems supports this kind of fine-grained IPI separation. Unfortunately, AIC does not: it only supports 2, and in fact was designed to have them be used in different ways (one is meant to be sent to other CPUs, while the other is for “self-IPIs” from one core to itself, which is sometimes necessary). To make this work for Linux, we had to implement a “virtual” interrupt controller. The AIC driver internally manages up to 32 different events that can be pending for any given CPU core, and funnels them all through a single hardware IPI for that core. When the IPI arrives at that core, it checks to see which events are pending, and delivers them to Linux as if they were separate IPIs. The rest of Linux sees an interrupt controller that can handle up to 32 IPIs per CPU, even though the hardware only supports 2 (and we only use one). Phew!
Writing drivers for even simple interrupt controllers like AIC is complex. There are many subtleties to interrupt handling, and if the code is slightly wrong it can cause frustrating heisenbugs that only appear under rare sequences of events – but can hang your entire OS, making debugging nearly impossible. Printing debug info from interrupt handlers is tricky, because changing the timing can make bugs go away, and it can also make everything too slow to be usable. Adding a software IPI multiplexer further complicates things, as we now have to emulate in software what is typically handled by the hardware: getting it wrong could cause things like IPIs going missing due to race conditions.
While trying to understand these details to ensure that the AIC code is correct, I found myself deep in a rabbit hole researching the details of memory ordering and memory barriers on AArch64, and even found a subtle bug in the ARM64 Linux implementation of atomic operations! Talking about this subject would be an entire multi-part saga, but if you are brave enough to want to learn more, I recommend Will Deacon’s talks, such as this one and this one. In particular, this commit answered a lot of questions, and Will also helped clear up some of my remaining doubts. Being confident about the memory model and the soundness of the AIC code will help avoid frustrating debugging sessions much further down the line. Just imagine if we had to trace a subtle GPU hang issue that only happens when you do certain things in a game (but only sometimes, and it takes an hour to reproduce) down to an AIC driver race condition!
For better or for worse, the M1 is particularly good at exposing these kinds of subtle bugs. It is such a highly out-of-order machine that it tickles race conditions which you would never hit on other CPUs. While debugging an earlier m1n1 issue, we even saw it (legitimately) speculating its way out of an interrupt handler… while to the code it seemed like it was still halfway through the handler printing debug info! The underlying problem there turned to have been caused by a subtle misconfiguration of the MMU, which gives you an idea of just how inextricably tied together all these core systems are, and how tricky to debug they can be.
Interestingly, the M1 chip actually has a bit of the standard GIC in it – specifically, it supports natively virtualizing the low-level bits of a GIC to VM guests! This allows for much higher performance interrupt handling, since otherwise the VM hypervisor has to emulate every little detail of the interrupt controller, which means every interrupt requires many calls into hypervisor code and back. Oddly enough… the macOS Hypervisor Framework does not support this (at the time of writing), requiring VM hypervisors to do full GIC emulation in software! We have already tested it and it works, and I’ve been working with Marc Zyngier on the peculiarities of running VMs on these chips; he already has Linux virtual machines booting on top of KVM running on the Asahi Linux kernel on M1 Macs. It’s too early for benchmarks, but we expect that without that support in macOS, once other bits and pieces are in place, this will make native Linux-on-Linux VMs faster than Linux-on-macOS VMs, especially for IPI-heavy workloads.
Finicky FIQs
Next up, every OS needs a system timer to work. When your computer runs multiple applications, the OS needs to be able to switch between them on the same CPU core, to make multitasking work. It also needs to be able to schedule things to be done at certain points in time, from writing buffered data to disk to showing the next frame of a YouTube video to making the clock in your task bar tick forward. All of this is accomplished with some kind of timer hardware, which the OS can program to deliver an IRQ at some point in the future.
AArch64 includes a specification for system timers, and the M1 implements these standard timers as you would expect. But there is a platform-specific bit: the timers need to deliver their interrupt via some IRQ controller. On GIC systems, that is of course via GIC (though the specific interrupt numbers used can vary from system to system). On Apple Silicon, therefore, you’d expect this to end up in AIC.
Yet, making the timers fire and asking AIC to tell us about pending interrupts yielded… nothing. What gives? Apple had yet another surprise for us… you see, the M1’s timers cannot deliver IRQs at all. Instead, they only deliver FIQs.
When we said that AArch64 CPUs only have a single IRQ line, we didn’t mention its oft-neglected sister, the FIQ line. FIQs, or “Fast Interrupt Requests”, are a secondary interrupt mechanism. The “fast” bit refers to how they worked a bit more efficiently on older AArch32 systems, but on AArch64 this is now obsolete: FIQs and IRQs are effectively equal. On GIC systems, the OS can configure individual interrupts to go via IRQ or FIQ – and most AArch64 systems reserve FIQ for use by the secure monitor (TrustZone), so Linux cannot use it. And so, Linux does not use FIQs. At all. AArch64 Linux will panic if it gets a FIQ, as it never expects them.
Without FIQ support, there are no timers on M1, so support isn’t optional. This became yet another major change to the Linux AArch64 support needed by Apple Silicon. Simply adding support for FIQs is easy (at its simplest, it just involves mechanically copying the way IRQs are handled to handle FIQs in a similar way), but there are many different ways to go about the finer details, including deciding how to handle FIQs for systems that don’t need them, and whether to keep FIQs enabled everywhere or disable them on systems that don’t use them.
In the end, after considering several alternatives and iterating through several approaches, Mark Rutland from the Linux ARM64 team volunteered to take over this piece of the puzzle and bring FIQ support to Linux.
There are other things that deliver FIQs too: there is actually a FIQ-based “Fast IPI” mechanism, which we aren’t using yet. There are also hardware performance counters that use it. Effectively, FIQs are used by hardware that is built into individual CPU cores or core clusters, and IRQs are used by the single shared AIC peripheral which manages hardware shared among all CPUs. However, as yet another additional pain point, there is no FIQ controller at all. While AIC serves as an IRQ controller, all of these FIQ sources are “mixed together” (ORed) into a single FIQ, with no way to tell them apart in a centralized manner. Instead, the FIQ handling code has to go and check each of these FIQ sources one by one (in a unique way for each one, as it needs to peek into the specific device registers), figure out which one needs attention, and only then deliver the interrupt to the driver for that device. This is very ugly, and we don’t really know why Apple didn’t think to include a trivial “FIQ controller”. Even a single register indicating the status of each FIQ source as one bit would’ve sufficed. We’ve looked for it, even exhaustively searching all CPU registers, but it sadly doesn’t seem to exist.
What the M1 does have are some extra special features for handling the timer interrupts for VM guests (thankfully, as this is practically a requirement to make VMs work sanely at all). We’ve also reverse engineered these, and they’re now used as part of Marc’s work getting KVM up and running.
On top of the core FIQ support patches, we opted to handle distributing FIQs to downstream device drivers in the AIC driver (even though they are strictly speaking not part of AIC), in order to allow for closer coupling between these paths in the future. This may be needed if we switch from AIC IPIs via IRQ to “Fast IPIs” via FIQ.
An Exyting History
Running Linux on a device is great, but what use is it if you can’t actually interact with it? To be able to get dmesg logs and interact with a Linux console, we need a UART driver for the M1. There are quite a few UART variants out there, though the most popular types are based around the PC standard 16550 UART, which is these days often integrated into all kinds of ARM SoCs. Of course, Apple being Apple, they probably rolled their own instead… right?
Nope! But it’s not at 16550, either. The M1 uses a… Samsung UART?
You see, Apple’s first iPhones ran on Samsung SoCs, and even as Apple famously announced that they were switching to their own designs, the underlying reality is that there was a slower transition away from Samsung over multiple chip generations. “Apple Silicon” chips, like any other SoC, contain IP cores licensed from many other companies; for example, the USB controller in the M1 is by Synopsys, and the same exact hardware is also in chips by Rockchip, TI, and NXP. Even as Apple switched their manufacturing from Samsung to TSMC, some Samsung-isms stayed in their chips… and the UART design remains to this day. We don’t know whether this means that Samsung’s intellectual property is in the M1, or whether Apple merely cloned the interface to keep it software-compatible (UARTs aren’t exactly hard to design), but either way this means that today’s Exynos chips and Apple Silicon still have something in common.
And so, Linux already has a driver for Samsung UARTs. But there’s a catch (of course there’s a catch). There isn’t a single “Samsung UART”. Instead, there are several subtly incompatible variants – and the one that Apple uses is not supported in the Linux Samsung UART driver.
Drivers supporting many variants of the same hardware can get quite messy, and even moreso for drivers as old as this one. Worse, the serial port subsystem in Linux dates back to the earliest versions, and brings with it yet another dimension of cruft: beware all ye who read on. And so, the challenge is figuring out how to integrate support for this new UART variant, without making the code worse. This means refactoring and cleanup! For example, Linux has an ancient concept of serial port types that is exposed to userspace (which means that these types can only ever be added, not removed, as the userspace API must remain backwards-compatible), but this is completely at odds with how devices are handled on modern Linux. There is absolutely no reason why userspace should care about what type a serial port is, and if it does it certainly shouldn’t use clunky TTY APIs with hardcoded define lists (that is what sysfs is for). Each existing Samsung UART variant had its own port type defined there (and there is even an unused one that was never implemented), but adding yet another one was definitely out of the question… so we refactored the driver to have an internal private notion of the UART variant, unrelated to the port type exposed to userspace. Apple Silicon UARTs just identify themselves as a 16550 to this legacy API, which nobody uses for anything anyway.
Yet another challenge is how this variant handles interrupts. Older Samsung UARTs had two independent interrupt outputs for transmit and receive, handled separately in the system’s interrupt controller. Newer Exynos variants handle this internally, with a little interrupt controller in the UART to handle various interrupt types and deliver them as a single one to the system IRQ controller. The Apple variant also does this, but in an incompatible way with different registers, so separate code paths had to be written for it.
On top of that, this UART variant only supports edge-triggered interrupts. An edge-triggered interrupt is an interrupt that fires when a given event occurs, and only on the instant on which it occurs: for example, when the UART transmit buffer becomes empty. Conversely, a level-triggered interrupt is one that fires as long as a given condition is true, and continues to fire until the condition is cleared: as long as the transmit buffer is empty. For various reasons, level-triggered interrupts are much easier to handle and are preferred by modern systems. While AIC itself uses level-triggered interrupts, and the interrupt from the UART itself is level-triggered, the internal events that drive it (such as transmit and receive buffers becoming empty or full) work only in an edge-triggered fashion! Other Samsung UART types support both modes, and Linux uses them in level-triggered mode. This turned into a problem for the Linux code that transmits data via the UART: the existing code worked by just turning on the transmitter, and then doing nothing. With everything configured in level-triggered mode, the empty transmit buffer immediately triggers an interrupt, and the interrupt handler in the driver will then fill the buffer with the first data to be transmitted. In edge-triggered mode this doesn’t work, because the buffer is already empty, not becoming empty. Nothing happens, and the driver never sends any data. We had to make the driver “prime” the transmit buffer immediately when data was ready to be sent to the device, as only once that first chunk of data is sent does the interrupt fire to request more.
Working out these quirks of the UART was doubly confusing because we were using m1n1 to run experiments, which is itself controlled via UART. Trying to figure out how a device works when your debug communications channel is the device itself can get very confusing! Thankfully, this is all done now, and m1n1 is much more pleasant to use to work on any other part of the hardware.
There is another driver that will have to go through the same treatment, though with a completely different lineage. The I²C hardware in the M1 chip comes from… P.A. Semi! It turns out that there is some obvious PowerPC legacy in the M1 after all, and its I²C peripheral is based on the one in PWRficient chips, including the one used in the AmigaOne X1000. Linux supports that platform, but the existing driver is very bare-bones. Fortunately, after contacting the author of the driver, it turns out he still owns a functioning X1000 and can test patches. We were able to get hardware documentation of that chip, to allow us to improve the driver and add missing features that should work on the X1000 (like interrupt support), as well as making any changes required for M1 support. As this driver is a dependency for getting the USB Type-C ports fully up and running, this work will be coming up very soon.
Penguins at Last
To anticlimactically wrap up the Linux bring-up saga, let’s talk about what we needed to do to get the Linux framebuffer console to work on the M1. If you were expecting another 2000 words here, I’m afraid you’ll be disappointed.
On PCs, the UEFI firmware sets up a framebuffer and you can run Linux with no proper display driver at all, using a driver called efifb. Apple Silicon Macs work in much the same way: iBoot sets up a framebuffer that the OS can use. All we need to do is use the generic simplefb Linux driver, and it just works, with no code changes at all. We only had to document some changes to the devicetree binding, because the code already supported some features that we needed but were not documented.
And just like that, after all that work, all it took was a couple lines in the devicetree to turn a blank screen into this:
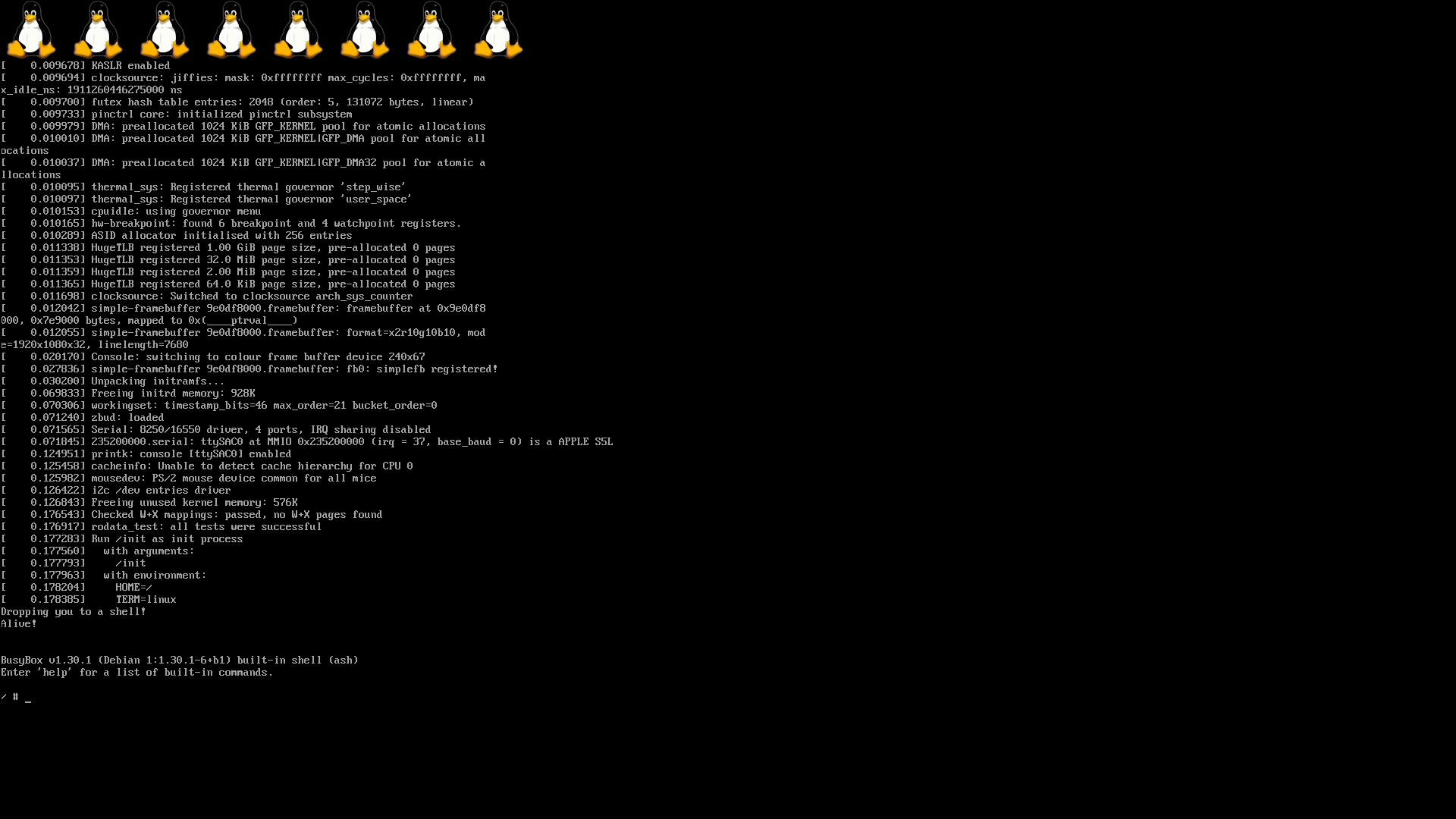
m1n1 now takes care of doing this properly, taking the framebuffer information (width, height, pixel format, stride, and base address) that iBoot gives us and sticking it into the devicetree for Linux to use.
Of course, this is just a firmware-provided framebuffer. As it is not a proper display driver, there is no way to change resolutions, handle display hotplug, or even put displays to sleep. It is sufficient for development and demos, but we will have to write a proper display controller driver in due course.
And then, of course, there is the GPU, which is not the display controller and is a logically separate piece of hardware. PC users often conflate these two, because they come packaged up into a single chip on a “graphics card”… but they are logically quite distinct, and on an SoC like the M1 there is about as much relationship between the display controller and the GPU as there is between the USB controller and the GPU. GPU support will be its own odyssey, so look forward to hearing more about it!
There’s Even More!
We could keep talking in depth for another 10000 words, but alas, this post is already too long. However, if you’d like to check out more things that have been going on in the community in these two months, here’s a list of things you shouldn’t miss:
- Alyssa’s work reverse engineering the M1 GPU (part 1, part 2)
- Dougall’s GPU ISA docs, CPU microarchitecture docs, and AMX instruction set docs
- Iris’ work bringing M1 support to QEMU
- Mark’s work porting U-Boot and OpenBSD to the M1. He even has PCIe support already!
- Sven’s work reverse engineering DART, Apple’s IOMMU
Our current Linux bring-up series is in its third version and being reviewed for upstream inclusion. If you’d like to see how the story of this article maps to code, check out the patches; and if you want to see how the process works, read the threads for versions 1 and 2. If all goes well and we don’t hit any new showstoppers, this should be on track to being merged into Linux 5.13. Stay tuned!
Asahi Linux wouldn’t be possible without the entire community of people who have jumped on to help move the project forward, from people new to embedded development to hardware engineers to seasoned kernel folks. If you are interested in contributing, check out our community page and join our IRC channels!
On a personal note, I’m trying to make Asahi Linux my full time job. If you like what I’m doing and would like to help me spend more of my time on the project, you can support me on Patreon and GitHub. Thanks to everyone who has pledged so far; this wouldn’t have been possible without you either!
Thanks to JMC47, David and Ridley for proofreading this article.